Python-文件系统
Python是 文件对象.write(),PHP是fwrite() 😀…
推荐参考资料:
《Python3 输入和输出》
《Python学习之路-11 (文件操作)》
一. 读写文件
Python提供了 input() 内置函数从标准输入读入一行文本,并将输入以字符串形式返回,默认的标准输入是键盘。
input 可以接收一个Python表达式作为输入,并将运算结果返回。
1 | str = input("请输入:"); |
使用到的方法:
- open(): 以某种读写模式打开一个文件,将会返回一个 file 对象;
- f.write(string) : 将 string 写入到文件中, 然后返回写入的字符数;
- f.read(size): 将读取一定数目的数据, 然后作为字符串或字节对象返回;
- f.readline() : 从文件读取整行,包括 “\n” 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 “\n” 字符。;
- f.readlines() : 将返回该文件中包含的所有行;
- f.tell() : 返回文件对象当前所处的位置, 它是从文件开头开始算起的字节数;
- f.seek() : 如果要改变文件当前的位置, 可以使用 f.seek(offset, from_what) 函数;
- f.close() : 当你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常。
1.1 open()
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。即a = open(file, mode);
| 语法格式 | 参数说明 | 返回类型 |
|---|---|---|
| open(file, mode, buffering, encoding=None,    errors=None, newline=None,    closefd=True, opener=None) |
file: 必需,文件路径(相对或者绝对路径)。 mode: 可选,文件打开模式 buffering: 设置缓冲 encoding: 一般使用utf8 errors: 报错级别 newline: 区分换行符 closefd: 传入的file参数类型 opener: |
文件对象 |
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
- |打开一个文件进行更新(可读可写)。
U |通用换行模式(不推荐)。
r |以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
rb |以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。
一般用于非文本文件如图片等。
r+ |打开一个文件用于读写。文件指针将会放在文件的开头。
rb+ |以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。
w |打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。
如果该文件不存在,创建新文件。
wb |以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有
内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
w+ |打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。
如果该文件不存在,创建新文件。
wb+ |以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,
即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。
a |打开一个文件用于追加(不能读)。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,
新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
ab |以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,
新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
a+ |打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。
文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+ |以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。
如果该文件不存在,创建新文件用于读写。
下图很好的总结了这几种模式:
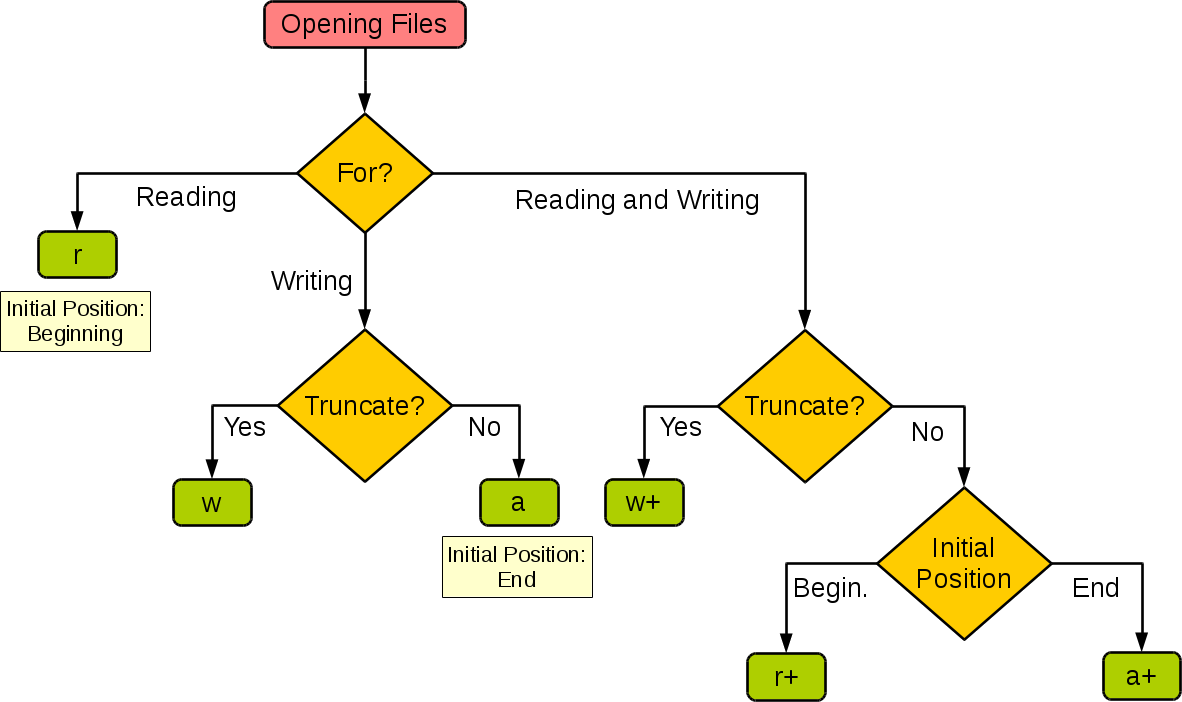
| 模式 | 读 | 写 | 创建 | 覆盖 | 指针在开始 | 指针在结尾 |
|---|---|---|---|---|---|---|
| r | ✔ | ✔ | ||||
| r+ | ✔ | ✔ | ✔ | |||
| w | ✔ | ✔ | ✔ | ✔ | ||
| w+ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| a | ✔ | ✔ | ✔ | |||
| a+ | ✔ | ✔ | ✔ | ✔ |
总结:
- w 和 a 都是写入不能读内容,前者是覆盖,后者是追加内容。
- w+ 和 a+ 都是写入且能读内容,前者是覆盖,后者是追加内容。
以下实例将字符串写入到文件 foo.txt 中:
1 | # 打开一个文件 |
- 第一个参数为要打开的文件名。
- 第二个参数描述文件如何使用的字符。 mode 可以是
r如果文件只读,w只用于写 (如果存在同名文件则将被删除), 和a用于追加文件内容; 所写的任何数据都会被自动增加到末尾.r+同时用于读写。 mode 参数是可选的;r将是默认值。
1.2 f.write()
| 语法格式 | 参数说明 | 返回类型 |
|---|---|---|
| f.write(string) | 将 string 写入到文件中 | 返回写入的字符数 |
1 | # 打开一个文件 |
1.3 f.read()
为了读取一个文件的内容,调用 f.read(size), 这将读取一定数目的数据, 然后作为字符串或字节对象返回。
size 是一个可选的数字类型的参数。 当 size 被忽略了或者为负, 那么该文件的所有内容都将被读取并且返回。
注意:f.read(size)必须在r或者r+模式下来读取内容。
| 语法格式 | 参数说明 | 返回类型 |
|---|---|---|
| f.read(size) | 文件读取指定的字节数(读取的时候文件内容的 一个字符按一个字节来读),如果未给定或为负则读取所有 |
字符串或字节对象返回 |
以下实例假定文件 foo.txt 已存在(上面实例中已创建):
1 | '''foo.txt文件内容为16845654316532''' |
1.4 f.close()
在文本文件中 (那些打开文件的模式下没有 b 的), 只会相对于文件起始位置进行定位。
当你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常。如下:
1 | # 打开一个文件 |
由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用try ... finally来实现:
1 | '''foo.txt内容为16845654316532''' |
但是每次都这么写实在太繁琐,所以,Python引入了with语句搭配as来自动帮我们调用close()方法:
1 | '''foo.txt内容为16845654316532''' |
1.5 f.readline()
| 语法格式 | 参数说明 | 返回类型 |
|---|---|---|
| fileObject.readline(size) | size为从文件中读取的字节数。 从文件读取整行,(包括 “\n” 字符。) |
size非负数则返回指定大小的字节数, 包括”\n”字符。 |
实例
以下实例演示了 readline() 方法的使用:
文件 runoob.txt 的内容如下:
www.runoob.com'\n'www.runoob.comwww.runoob.comwww.runoob.comwww.runoob.com
1 | # 打开文件 |
1.6 f.readlines()
概述
readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表,该列表可以由 Python 的 for… in … 结构进行处理。 如果碰到结束符 EOF 则返回空字符串。
如果碰到结束符 EOF 则返回空字符串。
关于EOF可参考:[文件结束符EOF]
| 语法格式 | 参数说明 | 返回类型 |
|---|---|---|
| fileObject.readlines( ) | 无参数 | 返回列表,包含所有的行。 |
实例
以下实例演示了 readline() 方法的使用:
文件 runoob.txt 的内容如下:
www.runoob.com'\n'www.runoob.comwww.runoob.comwww.runoob.comwww.runoob.com
1 | 请自行区分下面两种输出方式: |
1.7 f.tell()
f.tell() 返回文件对象当前所处的位置, 它是从文件开头开始算起的字节数。
| 语法格式 | 参数说明 | 返回类型 |
|---|---|---|
| f.tell() | 无参数 | 返回文件指针的当前位置(整数) |
实例
以下实例演示了 readline() 方法的使用:
文件 runoob.txt 的内容如下:
www.runoob.com'\n'www.runoob.comwww.runoob.comwww.runoob.comwww.runoob.com
1 | # 打开文件 |
1.8 f.seek()
如果要改变文件当前的位置, 可以使用 f.seek(offset, from_what) 函数。
from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾。from_what 值为默认为0,即文件开头。例如:
seek(x,0) : 从起始位置即文件首行首字符开始移动 x 个字符
seek(x,1) : 表示从当前位置往后移动x个字符
seek(-x,2):表示从文件的结尾往前移动x个字符
| 语法格式 | 参数说明 | 返回类型 |
|---|---|---|
| f.seek(offset[, whence]) | offset: 开始的偏移量,也就是代表需要移动偏移的字节数, 如果是负数表示从倒数第几位开始。 whence:可选,默认值为 0。给 offset 定义一个参数, 表示要从哪个位置开始偏移;0 代表从文件开头开始算起, 1 代表从当前位置开始算起,2 代表从文件末尾算起。 |
无返回值 |
实例
以下实例演示了 readline() 方法的使用:
文件 runoob.txt 的内容如下:
www.runoob.com'\n'www.runoob.comwww.runoob.comwww.runoob.comwww.runoob.com
1 | # 打开文件 |
1.9 file 对象的方法
| 序号 | 方法及描述 |
|---|---|
| 1 | file.close() 关闭文件。关闭后文件不能再进行读写操作。 |
| 2 | file.flush() 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 | file.fileno() 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 | file.isatty() 如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 | file.next() 返回文件下一行。 |
| 6 | file.read([size]) 从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 | file.readline([size]) 读取整行,包括 “\n” 字符。 |
| 8 | file.readlines([sizeint]) 读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| 9 | file.seek(offset[, whence]) 设置文件当前位置 |
| 10 | file.tell() 返回文件当前位置。 |
| 11 | file.truncate([size]) 从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断; 截断之后后面的所有字符被删除,其中 Widnows 系统下的换行代表2个字符大小。 |
| 12 | file.write(str) 将字符串写入文件,返回的是写入的字符长度。 |
| 13 | file.writelines(sequence) 向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
二. 在内存读写
可参考:
[StringIO和BytesIO]
[Python文件读写、StringIO和BytesIO]
IO在计算机中指Input/Output,也就是输入和输出。由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘、网络等,就需要IO接口。
由于CPU和内存的速度远远高于外设的速度,所以,在IO编程中,就存在速度严重不匹配的问题。举个例子来说,比如要把100M的数据写入磁盘,CPU输出100M的数据只需要0.01秒,可是磁盘要接收这100M数据可能需要10秒,怎么办呢?有两种办法:
第一种是CPU等着,也就是程序暂停执行后续代码,等100M的数据在10秒后写入磁盘,再接着往下执行,这种模式称为同步IO;
另一种方法是CPU不等待,只是告诉磁盘,“您老慢慢写,不着急,我接着干别的事去了”,于是,后续代码可以立刻接着执行,这种模式称为异步IO。
很明显,使用异步IO来编写程序性能会远远高于同步IO,但是异步IO的缺点是编程模型复杂。
操作IO的能力都是由操作系统提供的,每一种编程语言都会把操作系统提供的低级C接口封装起来方便使用,Python也不例外。我们后面会详细讨论Python的IO编程接口。
注意,本章的IO编程都是同步模式,异步IO由于复杂度太高,后续涉及到服务器端程序开发时我们再讨论。
就单独说一下Python的input()和print():
input(): 在控制台把数据输入到内存中,然后从内存中把数据以字符串形式返回给调用处;
print(): 从内存中输出括号里的相对应的信息。
2.1 StringIO
很多时候,数据读写不一定是文件,也可以在内存中读写。
StringIO是IO模块中的类,所以使用的时候要引用模块: from io import StringIO
StringIO顾名思义就是在内存中读写str。
内存中,开辟的一个文本模式的buffer,可以像文件对象一样操作它;
当使用close()前写入的数据是使用追加模式;
当close方法被调用的时候,这个buffer会被释放;
好处:
一般来说,磁盘的操作比内存的操作要慢得多;内存足够的情况下,一般的优化思路是少落地,减少磁盘IO的过程,可以大大提高程序的运行效率。
使用到的方法:
- StringIO():创建一个StringIO对象,类似文件的
open()方法,创建的这个对象要赋值给一个变量; - f.write(‘String’):将字符String写入到内存,返回写入的字节数(一个字符按一个字节算);
- f.getvalue(size):从内存中读取size个字节(一个字符按一个字节算),若无参数则读取全部字节;
- f.readable():判断IO是否可读;
- f.writable():判断IO是否可写;
- f.seekable():指针是否可操作。
要把str写入StringIO,我们需要先创建一个StringIO,然后,像文件一样写入即可:
1 | from io import StringIO |
2.2 BytesIO
StringIO操作的只能是str,如果要操作二进制数据,就需要使用BytesIO。
BytesIO是IO模块中的类,所以使用的时候要引用模块:from io import BytesIO
内存中,开辟的一个二进制模式的buffer,可以像文件对象一样操作它;
当使用close()前写入的数据是使用追加模式;
当close方法被调用的时候,这个buffer会被释放;
使用到的方法和StringIO一样,不过一个读的是字符一个读的是字节。
BytesIO实现了在内存中读写bytes,我们创建一个BytesIO,然后写入一些bytes:
1 | from io import BytesIO |
file-like对象
类文件对象,可以像文件对象一样操作;
socket对象,输入输出对象(stdin、stdout)都是类文件对象
1 | from sys import stdout |
三. 操作目录
如果我们要操作文件、目录,可以在命令行下面输入操作系统提供的各种命令来完成。比如dir、cp等命令。
如果要在Python程序中执行这些目录和文件的操作怎么办?其实操作系统提供的命令只是简单地调用了操作系统提供的接口函数,Python内置的os模块也可以直接调用操作系统提供的接口函数。
具体方法:[Python3 OS 文件/目录方法]
打开Python交互式命令行,我们来看看如何使用os模块的基本功能:
1 | import os |
操作文件和目录
操作文件和目录的函数一部分放在os模块中,一部分放在os.path模块中,这一点要注意一下。查看、创建和删除目录可以这么调用:
1 | 查看当前目录的绝对路径: |
四. 序列化
参读资料:
《廖雪峰的官方网站 序列化》
《Python之数据序列化(json、pickle、shelve)》
《python3之序列化(pickle&json&shelve)》