Linux 标准 C 文件 I/O 管理
😊
1 标准 I/O 库
C 标准库中提供了标准 I/O 库(简称 stdio),它实现了跨平台的用户缓冲解决方案。 这个标准 I/O 库使用简单,且功能强大。
理论上,使用 ANSI C 标准编写的程序,是跨平台的,Windows 和 Linux 都遵守这一标准。在 Windows 平台使用 ANSI C 标准编写的代码可以不加修改拿到 Linux 平台下编译和运行。POSIX 标准编写的代码,是类 UNIX 系统遵循的标准,理论上使用这一标准编写的代码可以不加修改,移植到其他类 UNIX 系统上重新编译、运行。
ANSI C 标准函数是在 POSIX 标准函数的上层抽象,大部分 ANSI C 标准的函数都需要调用 POSIX 标准函数进行系统调用进入内核。
ANSI C 标准、POSIX 标准编写的程序区别:
| 类别 | ANSI C 标准 | POSIX 标准 |
|---|---|---|
| 是否使用应用层缓冲区 | 是 | 否 |
| 文件操作的接口 | 文件流(FILE 结构) |
文件描述符 |
| 是否必须进行系统调用 | 否 | 是 |
ANSI C 标准文件管理函数围绕文件流进行操作,而 POSIX 标准文件管理函数围绕文件描述符进行操作。
1.1 文件流
标准 I/O 程序集并不是直接操作文件描述符。相反,它们通过唯一标识符,即文件指针(fle pointer)来操作文件。在 C 标准库里,文件指针和文件描述符一一映射(对应)。文件指针为 FILE 的指针表示,定义在 <stdio.h> 中。
在标准 I/O 中,打开的文件称为“流”(stream)。流可以被打开用来读(输入流)、 写(输出流)或者二者兼有(输人/输出流)。——《Linux系统编程 第二版 3.2》
在 Linux 系统中,系统默认为每个进程开放三个流:标准输入流、标准输出流、标准错误输出流。分别对应三个文件:/dev/stdin、/dev/stdout、/dev/stderr。这三个标准流都是文件流,文件流需和一个文件进行关联。每个进程默认从标准输入流中读取数据,向标准输出流中输出信息,将错误信息输出到标准错误输出流。这三个流指针及其宏定义如下:
1 | /* /usr/include/stdio.h */ |
对于一个程序,常见的输入流有:键盘、文件、管道(pipe);常见的输出流有:显示器、文件、管道。
文件流:程序对文件的读写通过文件流来完成,即通过文件流指针 FILE 来实现。当使用 ANSI 库函数 fopen 函数打开一个文件后,返回一个文件流指针 FILE ,该指针和打开的文件进行关联,所有针对文件的读写操作都通过该文件流指针来完成。
文件流指针是一个 FILE 结构,其成员描述了该文件流的起始/结束地址、使用的缓冲区类型、缓冲区的大小等。如下:
1 | /* /usr/include/stdio.h */ |
关于文件流 FILE 成员具体解释请参考FILE结构体及漏洞利用方法。
如下代码,可以看到,标准 stdin、stdout、stderr 都是文件流指针。由于 ANSI C 标准要求这三个标准流都是宏定义,所以后面定义了同名宏。
1 | /* /usr/include/stdio.h */ |
参考资料:
- 《Linux系统编程 第二版 3.2》
- 《Unix 环境高级编程 第二版 第五章》
- 《Linux 高级程序设计 第三版 第四章》
- 《UNIX系统编程手册(上册)第十三章》
1.2 缓冲区介绍
根据数据的存储方式,可以将文件分为文本文件和二进制文件:
- 文本文件:ASCII 文件,每个字节存放一个 ASCII 码字符。便于对字符操作,存储量大,速度慢,文件以
EOF结束。 - 二进制文件:数据按照其在内存中的格式存储在磁盘文件。速度快,便于存放中间结果,如日志、临时文件(Windows 下 ETW 消费者拿到的内容、内存换页文件
C:\pagefile.sys)。
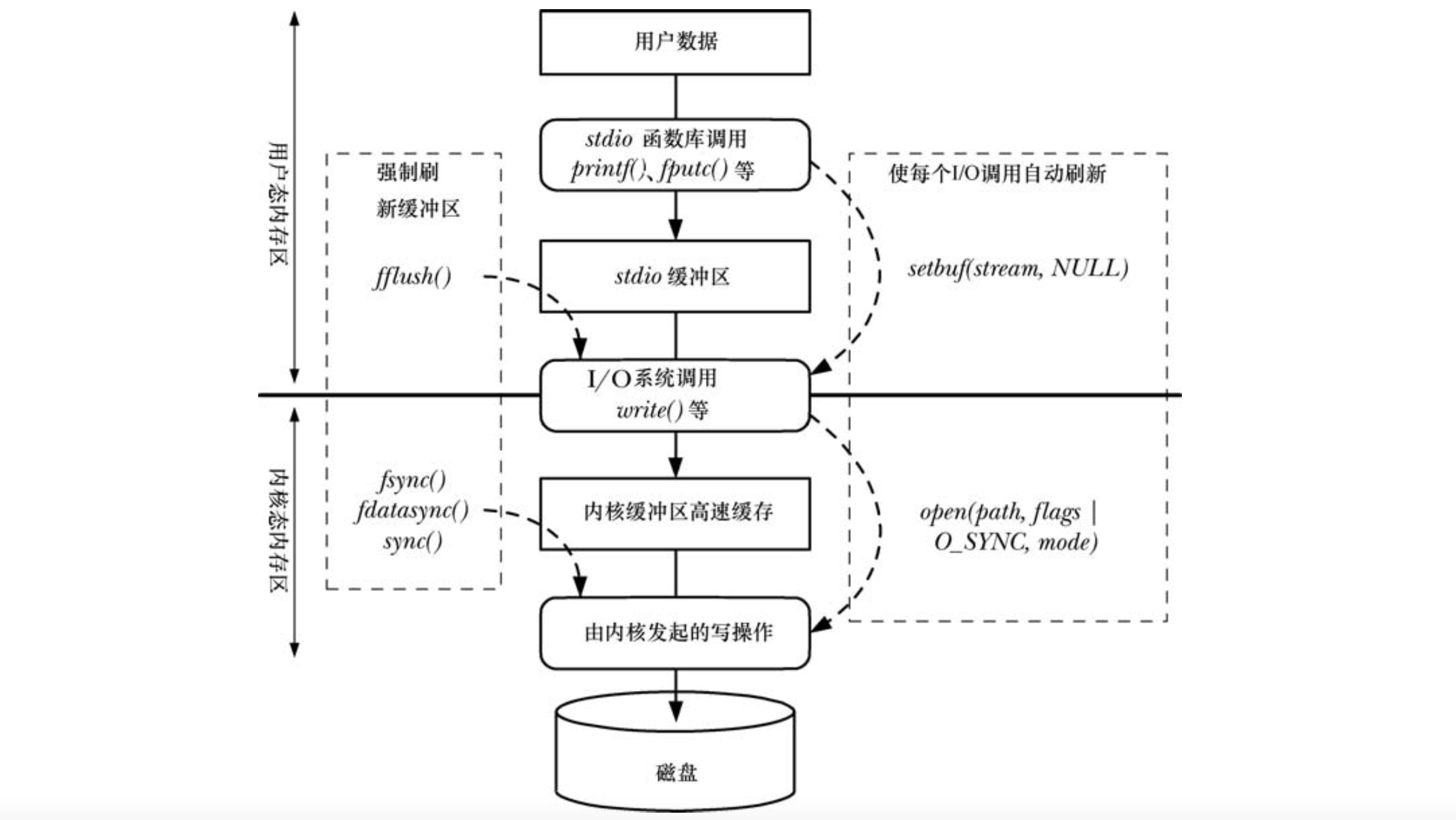
Linux 系统内核 I/O 操作和标准 C 语言库 I/O 函数(应用层)在操作磁盘文件时都会对文件进行缓冲。前者使用的缓冲区称为内核缓冲区,后者使用的缓冲区称为应用层文件缓冲区。
POSIX 标准下的 read/write 函数对文件进行读写时,并不会直接发起磁盘访问。而是在应用层用户空间缓冲区和内核缓冲区高速缓存进行数据复制传输,所以每次 read/write 都会引发系统调用,带来线程在应用层和内核层的切换,消耗性能。使用 read/write 函数后续的某个时刻,内核会将其缓冲区中的数据写入(刷新至)磁盘。
为了减少每次文件数据读写引发的系统调用,标准 C 语言函数库的 I/O 函数提供了应用层的缓冲区(也叫做 stdio 缓冲区),该缓冲区位于用户态内存区。以下三种情况,stdio 库才会调用 write 进行系统调用,将数据传递到内核高速缓冲区(位于内核态内存区):
- 当缓冲区填满时。
- 使用
fflush刷新应用层缓冲区时。 - 当关闭流时,即调用
fclose函数。
下图概括了 stdio 函数库和内核所采用的缓冲(针对输出文件),以及对各种缓冲类型的控制机制。从图中自上而下,首先是通过 stdio 库将用户数据传递到 stdio 缓冲区,该缓冲区位于用户态内存区。当缓冲区填满时,stdio 库会调用 write 系统调用,将数据传递到内核高速缓冲区(位于内核态内存区)。最终,内核发起磁盘操作,将数据传递到磁盘。
1.3 I/O 标准缓冲区类型
本文关注应用层的文件读写缓冲区,即标准 C 语言库使用的缓冲区,内核缓冲区后续学习启动时再分析。
用户缓冲 I/O 实在用户空间而非内核空间完成(在内核中,所有文件操作都是基于块大小来执行),在应用层,对文件的访问可分为带缓冲区的文件操作和非缓冲文件操作。标准 I/O 提供了 3 种类型的缓冲区:全缓冲区、行缓冲区和无缓冲区。
| 缓冲类型 | 说明 |
|---|---|
| 全缓冲 | 1、文件读写是基于用户缓冲区完成的。可以为打开的文件申请一块内存作为文件读写缓冲区(标准 C 库函数 sethuf 默认大小为 BUFSIZ,定义在 stdio.h)。2、一般在对磁盘上的文件读写时,使用全缓冲。 3、当用户缓冲区满、调用 fflush、或者 fclose 关闭文件流时,才会调用到 read/write 将用户缓冲区数据读写到内核缓冲区。 |
| 行缓冲 | 1、数据读写大小单位是一行,其大小在 libio.h 中定义,CentOS 7.x 中为 1024 字节,大小固定。2、一般用于终端的输入输出。 3、当遇到换行符或者缓冲区满时,才会引发缓冲区的刷新。 |
| 无缓冲 | 1、数据读写不带缓冲区,标准 C 库函数对数据读写时不进行缓冲。比如使用 fopen 函数打开文件流,如果不使用 setbuf/setvbuf 等函数手工指定缓冲区的话,数据读写是不知用用户缓冲区的。2、标准错误输出流 stderr 是不带缓冲区的,每次都会引发 I/O 操作,导致系统调用。 |
ISO C要求下列缓冲特征:
- 当且晋档标准输入输出不涉及交互式设备时,才会使用全缓冲。
- 标准出错绝对不是全缓冲。
在很多系统中默认:
- 磁盘文件使用全缓冲
- 涉及终端设备使用行缓冲
- 标准错误输出流无缓冲
FILE->_flags 高 2 字节为 magic,低 2 字节才当做 flag 使用,表示 I/O 缓冲类型。
1 | /* /usr/include/libio.h |
主要关注:
#define _IO_UNBUFFERED 2:无缓冲区。#define _IO_LINE_BUF 0x200:使用行缓冲区。
1 | if(stdin->_flags & _IO_UNBUFFERED) |
如果没有匹配这两中缓冲类型那就是全缓冲(libio.h 中没有定义全缓冲的类型)
1.4 设置缓冲区
打开流后,必须要在使用其他任何 stdio 函数之前调用 setbuf/setvbuf 等函数设置好缓冲区,不同的缓冲区类型将会影响流操作。
1 | /* /usr/include/stdio.h */ |
关于 setvbuf 函数的参数:
参数 3 mode:指定缓冲区的类型。
1 | /* /usr/include/stdio.h */ |
| 缓冲类型 | 说明 |
|---|---|
_IONBF(2) |
1、无缓冲,每个 stdio 库函数将立即调用 write 或者 read 进行系统调用。2、此时将会忽略 buffer、size 两个参数(不管被指定为多少都不会使用)。3、无缓冲时,缓冲区的大小为 1 byte。 |
_IOLBF(1) |
行缓冲,此时必须指定 buffer、size 两个参数。 |
_IOFBF(0) |
全缓冲。 1、 buffer != NULL,此时 read/write 使用该缓冲区进行数据读写,若 size != 0则会使用指定 size 大小的缓冲区;如果 size == 0 则无缓冲区(此时缓冲区大小为 1 byte)。2、 buffer == NULL,不管 size 是多少,系统都会默认分配一块大小为 BUFSIZ/2 = 0x1000 ß的缓冲区给该文件流使用。 |
上表中 _IOFBF(0) 全缓冲下使用的 BUFSIZ 的定义:
1 | /* /usr/include/stdio.h */ |
设置缓冲区的注意事项:
- 打开文件得到文件流后,必须在调用任何其他 stdio 函数之前调用
setbuf/setvbuf等函数设置好缓冲区,不同的缓冲区类型将会影响流操作。 - 由于文件读写缓冲区是在整个程序中使用的,在使用自定义指定缓冲区的过程中,应该在堆中为该缓冲区分配一块空间(使用
malloc等函数),而不应是分配在栈上的函数本地变量。否则,函数返回时将销毁其栈帧,从而导致混乱。而setvbuf(fp, NULL, _IOFBF, 0)方式则不关心该问题,系统维护缓冲区。
示例:
1 |
|
1.5 缓冲区刷新
在章节 1.3 中已经提过以下行为会导致缓冲区的刷新:
- 全缓冲:当缓冲区写满、调用
fflush函数、 调用fclose函数。 - 行缓冲:当缓冲区写满、调用
fflush函数、 调用fclose函数、当遇到换行符\n。
以上行为,会导致对应类型的缓冲区进行刷新,所谓的刷新,即表示强制将用户缓冲区(stdio 标准缓冲区)中的数据,通过调用 write 函数传送给内核缓冲区。
关于 fflush 函数:
1 | /* /usr/include/stdio.h */ |
当参数 stream != NULL 时,刷新指定流用户缓冲区,当 stream == NULL,刷新所有流使用的 stdio 缓冲区。
举例说明:
1 |
|
2 文件操作
2.1 fopen/fclose
打开的文件称为流,在对文件进行操作之前,需要将它和流联系在一起。对文件的操作实际上是对流的操作。打开文件得到流是通过 fopen 函数来完成的:
1 | FILE* fopen(const char* filename, const char* mode); |
返回值:执行成功返回文件流指针,执行失败返回 NULL,并有相关的 errno 也会进行设置。
- 参数一为要打开文件的路径,可以使相对路径或绝对路径。
- 参数二为打开文件的模式,如下图。参数
mode必须是一个字符串,而不是字符,所以必须使用双引号。

注意:Windows 下打开二进制文件需要指定
b,但是在类 Unix 系统下不区分普通文件和二进制文件,所以在 Linux 下b实际上无意义。Linux 下不会像 Windows 那样区分普通文件和二进制文件,Linux 下把所有文件都当做二进制文件。
关闭流使用 fclose 函数,关闭指定的流之前,会将缓冲区的数据刷新到内核缓冲区,随之写到文件中。
1 | /* /usr/include/stdio.h */ |
2.2 读写文件流
标准 C 函数库提供了三种对文件流读写的方式:字符、行、块。
- 字符读写。每次从缓冲区中读写一个字符,可使用
fgetc/getc、fputc/putc函数。 - 行读写。每次从流中读写一行数据(遇到换行符终止,也算一行数据),可使用
fgets、fputs/puts函数。 - 块读写。每次按指定块大小对流数据进行读写,块的大小没有相关限制,可使用
fread、fwrite函数。
一、 字符读写
1 |
|
二、行读写
1 |
|
- 读取:
fgets函数将字符从stream读入s所指向的内存单元,直到读取n-1字符(最后一个字符是换行符)、换行符或遇到文件结束标志EOF为止,并将s最后一个空间置为NULL。 - 写入:
fputs函数将s指向的数据(以\0结尾字符串)写入文件中,但是不会将s的NULL(空字符)写入到文件。基于这一特点,这两个函数不能用来操作二进制文件,因为二进制文件中包含0的可能性很大。
三、块读写
1 |
|
关于 size_t 类型:
1 | // https://elixir.bootlin.com/linux/v3.10.108/source/include/linux/types.h#L54 |
2.3 ferror/feof
当使用 fgetc/fread 等函数读取数据失败时,这些函数返回失败信息做的很不友好,并不能直接返回失败的原因是因为文件读取错误还是读到了文件结束符 EOF。所以只能使用 ferror、feof 函数来判断是出现错误还是达到文件结尾。
1 |
|
源码参考 glibc/libio/ferror.c :
1 | int _IO_ferror (FILE *fp) |
- 可以看到在
glibc库的ferror.c文件中,会将_IO_ferror重命名为ferror函数。 - 在
_IO_ferror函数中,重点关注_IO_ferror_unlocked函数。 - 如果是文件流错误,即文件流
flags存在 _IO_ERR_SEEN 标志,则会返回true(1),否则返回false(0)。
关于 feof 同理可以查看 _IO_feof 来查看是否在存在 _IO_EOF_SEEN 标志。
clearerr 也只是用来清除 _IO_ERR_SEEN 和 _IO_EOF_SEEN 标志的。
1 |
2.4 文件流定位
在对文件流进行操作时,有一个指针指向流的当前读写位置,如果希望从特殊位置读写, 则需要通过函数修改当前读写位置。
每次读写文件时,都要先考虑当前文件流指针的位置,才能正确读写目标数据。注意这里描述的文件流指针并不是 FILE* 指针。
举例:如果使用
fwrite("123", 3, 1, fp)向目标文件写入3个字符(Unicode 编码),此时文件流指针指向位置为6(以字节为单位)。如果此时使用fread(buf, 3, 1, fp)读取刚才写入的数据是读取不到的,就是因为文件流指针的指向位置导致的。
ftell函数:返回当前文件流指针的位置(以字节为单位)。1
2
3
4
5/* /usr/include/stdio.h */
extern long int ftell (FILE *__stream) __wur;
返回值:
成功:返回当前指针位置距离文件开始的字节数
失败:返回 -1fseek函数:修改当前读写位置。1
2
3
4
5
6
7
8
9/* /usr/include/stdio.h */
extern int fseek (FILE *__stream, long int __off, int __whence);
参数说明:
__stream:文件流指针
__off:以参数 __whence 为基准的偏移量
__whence:要修改的基准位置
返回值:
成功:返回 0
失败:返回 -1关于
__whence基准位置的定义如下:1
2
3
4
5
6
7
8
9
10/* /usr/include/stdio.h */
/* The possibilities for the third argument to `fseek'.
These values should not be changed. */rewind函数:将读写指针移动到文件开头。等价于fseek(fp, 0, SEEK_SET)。1
2/* /usr/include/stdio.h */
extern void rewind (FILE *__stream);
如果中间没有 fseek、fsetpos 或 rewind,或者一个输入操作没有到达文件尾端,则在输入操作之后不能直接跟随输出(Unix环境高级编程 第二版 p113)。
3 格式化输入输出
因为数据在磁盘存储格式和人最易识别的格式不尽一致,格式化输入/输出,使数据按指定的格式(字符、某类型数据)输入,或者按需求输出人能够识别的数据。
3.1 格式输出
1 | __BEGIN_NAMESPACE_STD |
printf将格式化数据写到标准输出,fprintf写至指定的流,sprintf将格式化的字符送入数组__s中。sprintf在该数组的尾端自动加一个null字节,但该字节不包括在返回值中。- 注意,
sprintf函数可能会造成由__s指向的缓冲区的溢出。调用者有责任确保该缓冲区足够大。为了解决这种缓冲区溢出问题,引入了snprintf函数。在该函数中,缓冲区长度是一个显式参数,超过缓冲区尾端写的任何字符都会被丢弃。如果缓冲区是够大,snprintf函数就会返回写入缓冲区的字符数。与sprintf相同,该返回值不包括结尾的null字节。若snprintf函数返回小于缓冲区长度n的正值,那么没有截短输出。若发生了一个编码错误,snprintf则返回负值。 - 还有 4 种
printf族的变体类似于上面的 4 种,但是可变参数表(…〉代换成了arg。vprintf、vfprintf、vsprintf、vsnprintf。
格式输出函数的格式为:
1 | %[flags] [fldwidth] [precision] [lenmodifier] convtype |
| 字段 | 解释 |
|---|---|
| flags |  |
| fldwidth | 宽度。转换的最小字段宽度。如果转换得到的字符较少,则用空格填充它。字段宽度是一个非负十进制数,或是一个星号(*)。 |
| precision | 精度。整型转换后最少输出数字位数、浮点数转换后小数点后的最少位数、字符串转换后的最大字符数。精度是一个句点(.),后接一个可选的非负十进制整数或一个星号(*)。 宽度和精度字段两者皆可为 *。 |
| lenmodifier | 参数长度,其可能的取值示于表 5-6 中。 |
| convtype | 可选的。它控制如何解释参数。表5-7中列出了各种转换类型。 |
举例:
1 |
|
3.2 格式输入
执行格式化输人处理的是三个 scanf 函数。
1 | __BEGIN_NAMESPACE_STD |
scanf族用于分析输人宇符串,并将字符序列转换成指定类型的变量。格式之后的各参数 包含了变量的地址,以用转换结果初始化这些变量。- 格式说明控制如何转换参数,以便对它们赋值。转换说明以
%字符开始。除转换说明和空 白字符外,格式字符串中的其他字符必须与输入匹配。若有一个字符不匹配,则停止后续处理, 不再读输入的其余部分。
格式输入函数的格式为:
1 | %[*] [fldwidth] [lenmodifier] convtype |
| 字段 | 解释 |
|---|---|
| * | 可选的前导星号(*)用于抑制转换。按照转换说明的其余部分对输入进行转换,但转换结果并不存放在参数中。 |
| fldwidth | 最大宽度(即最大字符数)。 |
| lenmodifier | 要用转换结果初始化的参数大小。 |
| convtype | 类似于 printf 族的转换类型字段,但两者之间还有些差别。表 5-8 列出了 scanf 函数族支持的转换类型。 |
scanf 家族比 printf 家族好用的一个地方是,可以使用正则表达式来格式化输入。
举例如下:
1 | // 取仅包含 0 到 9 和小写字母的字符串 |