Linux 内核开发基础
😊
1 驱动程序定义
驱动程序是专用于控制和管理特定硬件设备的软件,因此也被称作设备驱动程序,在 Linux 内核中驱动主要有两种类型:模块(不控制或管理任何硬件设备)、设备驱动程序(字符设备、块设备、网络设备驱动程序)。我们给出的定义是:设备驱动程序把硬件功能提供给用户程序。——《Linux设备驱动开发一书(袁鹏飞翻译自 Linux Device Driver Development 2017 John Madieu)》
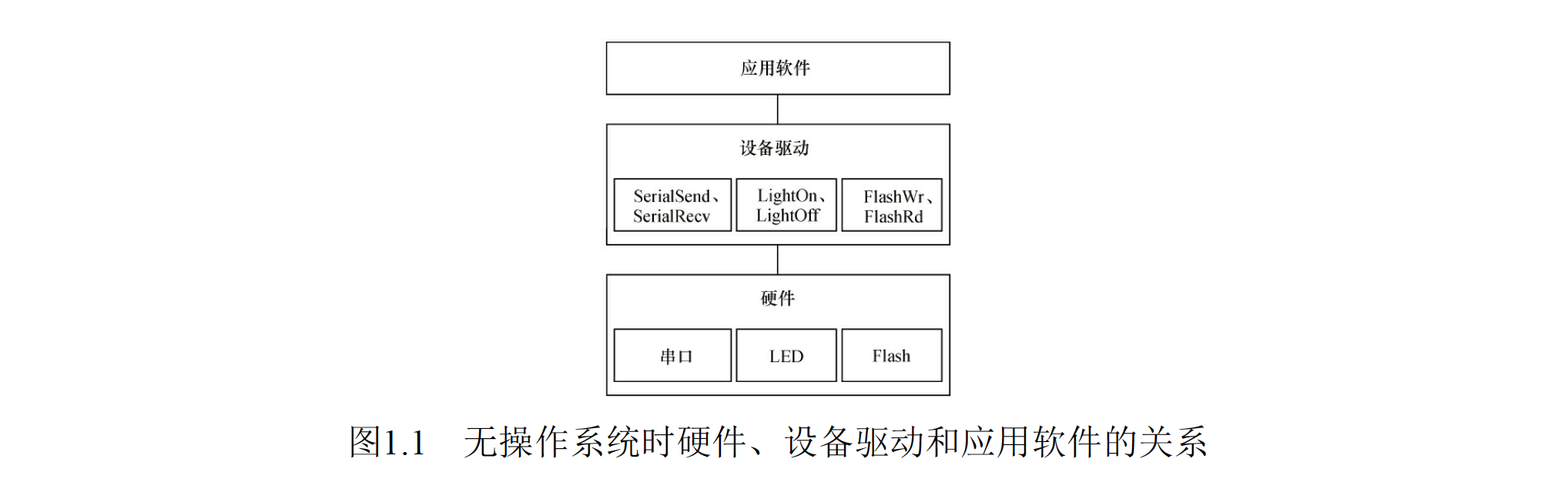
无操作系统时的设备驱动:
- 对于单任务架构的设备,功能比较单一、控制并不复杂的系统,譬如ASIC内部、公交车的刷卡机、电冰箱等,并不需要多任务调度、文件系统、内存管理等复杂功能,并不需要操作系统。
- 一个无限循环中夹杂着对设备中断的检测或者对设备的轮询是这种系统中软件的典型架构。
- 应用软件没有跨越任何层次就直接访问设备驱动的接口。
![3.png]()
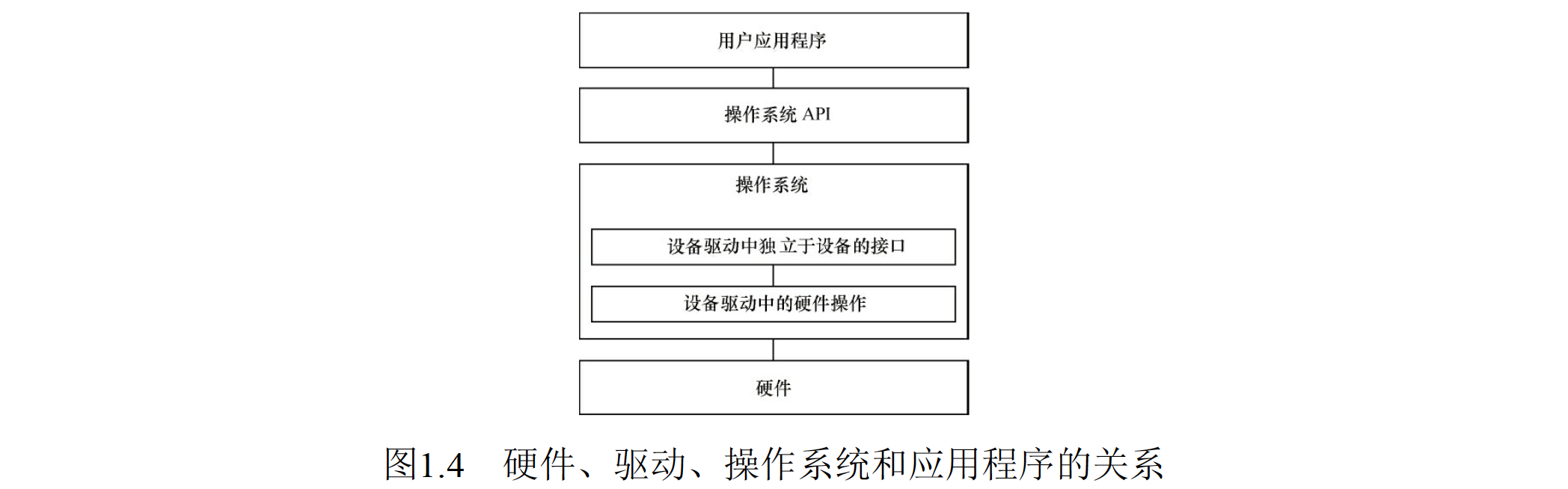
有操作系统时的设备驱动:驱动变成了连接硬件和内核的桥梁。操作系统对外提供 API,不再给应用软件工程师直接提供接口。
![4.png]()
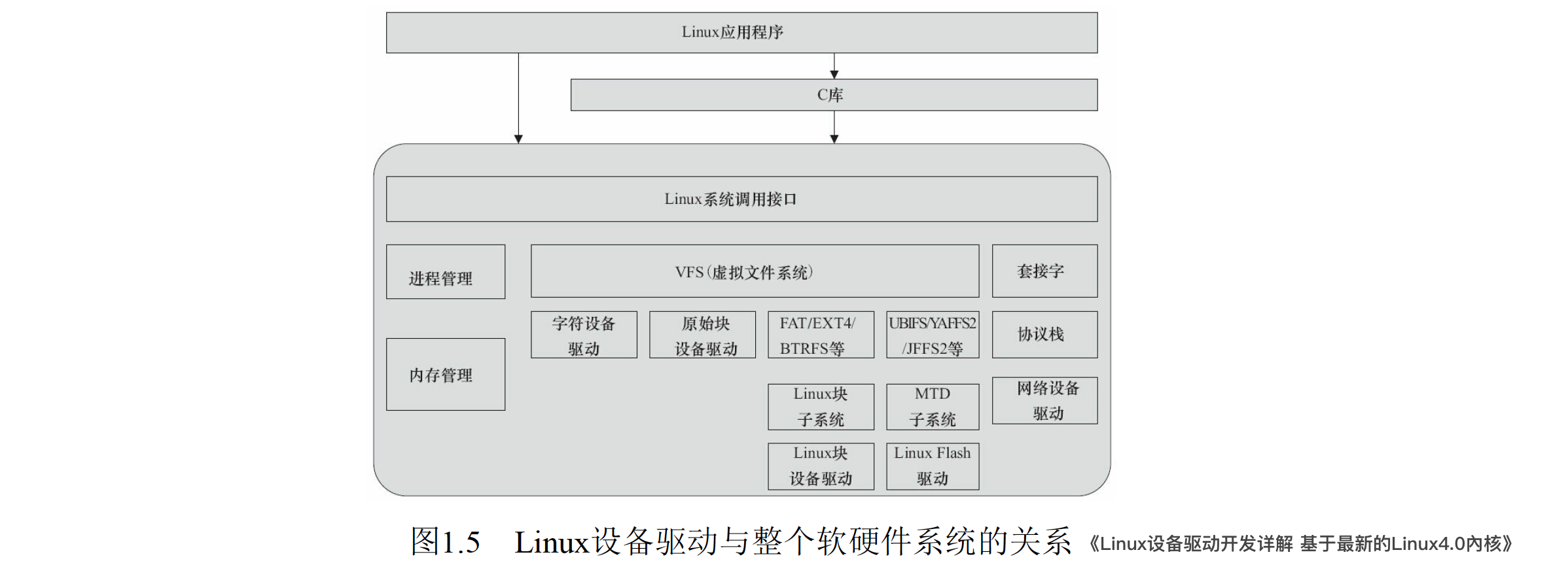
1.1 驱动程序分类
Linux 中驱动程序对应的设备分类:字符设备、块设备、网络设备。
- 字符设备:I/O 是以字节流发送接收的,包括终端设备、串口设备、虚拟设备(伪设备,不表示任何硬件)。支持字节或字符来读写,顺序读取,不支持随机读取
- 块设备:I/O 是以 2 的幂次方个字节的数据块大小进行发送接收的,包括硬盘等。数据需要通过内核的缓冲区进行缓存,驱动-内核缓冲区-设备进行交互,可进行随机读取。编写块设备的驱动程序比字符设备驱动程序复杂很多,因为要使用到内核的缓存机制。
- 网络设备:网卡也可以通过设备驱动进行控制(但是内核中属于特殊情况),但是网卡不可以通过设备文件进行访问,原因是在网络通信期间,数据打包到了各种协议层中(不在文件上)。在接收数据时,内核必须针对各层协议进行处理,对数据包进行拆包和分析;在发送数据时,内核必须根据各层协议的要求对数据进行打包,然后才能发送。为了支持通过文件接处理网路连接,Linux 使用了源于 BSD 的套接字抽象,套接字可以看做是应用程序、文件接口、内核网络实现三者之间的代理。
每一个字符设备或块设备在文件系统中都有一个特殊设备文件与之对应,这个文件就是设备带点。网络设备在文件系统的 /dev 目录中没有节点,应用层可以通过套接字访问网络设备。
Linux 操作系统中的网络设备是一类特殊的设备。Linux 的网络子系统主要是基于 BSD UNIX 的 socket 机制。在网络子系统和驱动程序之间定义有专门的数据结构(sk_ buff) 进行数据的传递。Linux 操作系统支持对发送数据和接收数据的缓存,提供流量控制机制,也提供对多种网络协议的支持。
Linux 系统为每个设备分配了一个主设备号与次设备号,主设备号唯一标识了设备类型,次设备号标识具体设备的实例。由同一个设备驱动程序控制的所有设备具有相同的主设备号。从设备号则用来区分具有相同主设备号的不同设备。
《Linux 驱动程序开发实例第 2 版 1.1.7》
除网络设备外,字符设备和块设备都能够被映射到 Linux 文件系统的文件和目录中,通过系统调用接口 open/read/write/close 等进行设备访问。
块设备的两种访问方法(无法通过 cat/less/more 访问):
使用
dd命令。dd if=/dev/sda of=/tmp/out.txt bs256 count=1 skip=512,/tmp/out.txt 文件内容就是从块中读到的内容、bs 是块大小、count 表示连续读几块 、skip 是从第几块开始读。最后hexdump out.txt内容即可。在块设备上建立文件系统(如 EXT4),然后以文件路径的形式对设备进行访问。
如下两图,内核提供了一个额外的软件层(Virtual Filsystem,VFS 虚拟文件系统),将各种底层文件系统的具体特性与应用层、系统内核本身进行隔离。
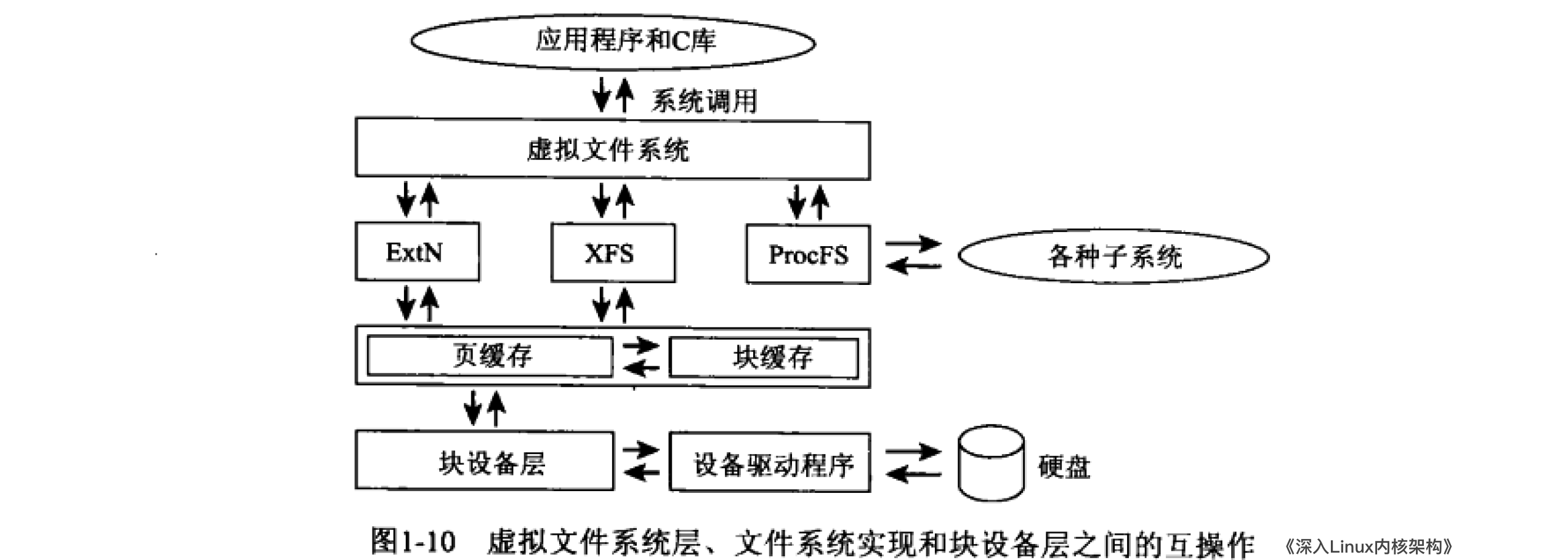
1.2 驱动的加载分类
Linux 内核中的大部分驱动程序是以模块的形式进行编写的,内核模块也叫做动态可加载内核模块(Loadable Kernel Module,LKM)。内核模块可单独编译成一个 ELF 模块(可动态加载和卸载,以 .ko 为扩展名),也可直接编译进 Linux 内核(需要重新编译内核)。但是一般将驱动编译成独立的模块,更加灵活加载、卸载、调试。——《Linux 驱动程序开发实例第 2 版 1.1.2》。
2 内核源码结构
Linux 内核源码开源,下载地址 https://mirrors.edge.kernel.org/pub/linux/kernel/ ,下载对应版本压缩包即可。在线查看地址 https://elixir.bootlin.com/linux/latest/source 。
版本编号:
- 2.6 之前,使用
x.y以主次版本号表示,y偶数为稳定版,奇数为开发版。- 2.6—2.6.39,使用
x.y.z以主次修订版本号表示。x当有向后不兼容的 API 更改时,它会增加;y再向后兼容的基础上增加新功能时,它会增加;z有新的补丁版本时,它会增加。- 3.0—3.20,采用
x.y以主次版本号表示,有补丁版本时需要z。- 4.0 之后,以
x.y形式,有补丁版本时需要z。
Linux 内核源码也叫做 Linux kernel source tree,本节内容参考 Linux Kernel源代码结构。
Linux 内核源码主要分成三个部分:说明文件、配置文件、代码文件。
2.1 说明文件
顶层目录下的文件:
| 文件名 | 描述 |
|---|---|
| README | Linux内核说明文档,简要介绍了 Linux 内核的背景,描述了配置和 build 内核需要什么。 |
| COPYING | 版权声明。发布内核源代码所依据的许可条款。内核是在 GNU GPL-2.0 许可证下发布的(GNU GPL 是 GNU 通用公共许可证)。 |
| CREDITS | Linux 内核贡献人员列表。 |
| MAINTAINERS | Linux 维护人员信息。 |
| REPORTING-BUGS | 报告 Bug 的流程及模板。 该文档在 v4.9 中移至 Documentation/admin-guide/reporting-bugs.rst。 |
Documentation/ 目录下的文件:
| Documentation/ | Description |
|---|---|
| 00-INDEX | Documentation/ 下各目录的内容。 该文档在 v4.19 中被删除. |
| email-clients.txt | 使用邮件发送 patch 时, 需要对邮件客户端进行特殊配置。 |
| Changes | 列出了成功编译和运行内核所需的各种软件包的最小集合。 |
| CodingStyle | 描述了 Linux 内核编码风格, 和一些隐藏在背后的基本原理。 所有的想加入内核的新代码应当遵循这篇文档的指导。 绝大数的内核代码维护者只愿意接受那些符合这篇文档描述的风格的补丁, 许多内核开发者也只愿意审查那些符合 Linux 内核编码风格的代码。 |
| development-process | Linux 内核开发过程。 |
| SubmittingPatches SubmittingDrivers SubmitChecklist | 描述了如何成功的创建和向社区递交一个补丁, 包括:邮件内容、邮件格式、发送者和接收者。 遵循文档里提倡的规则并不一定保证你提交补丁成功 (因为所有的补丁遭受详细而严格的内容和风格的审查), 但是不遵循它们, 提交补丁肯定不成功。 |
| stable_api_nonsense.txt | 这篇文档描述了有意决定在内核里没有固定内核API的基本原因, 这对于理解 Linux 的开发哲学非常关键, 也对于从其他操作系统转移到 Linux 上的开发人员非常重要。 |
| SecurityBugs | 如果你确知在 Linux Kernel 里发现了 security problem, 请遵循这篇文档描述的步骤, 帮助通知内核的开发者们并解决这类问题。 |
| ManagementStyle | 这篇文档描述了 Linux 内核开发者们如何进行管理运作, 以及运作方法背后的分享精神(shared ethos)。 这篇文档对于那些内核开发新手们(或者那些好奇者)值得一读, 因为它解决或解释了很多对于内核维护者独特行为的误解。 |
| stable_kernel_rules.txt | 这篇文档描述了一个稳定的内核版本如何发布的规则, 以及需要做些什么如果你想把一个修改加入到其中的一个版本。 |
| kernel-docs.txt | 关于内核开发的外部文档列表。 |
| applying-patches.txt | 描述了什么是补丁(patch), 以及如何将它应用到内核的不同开发分支(branch)上。 |
| kbuild/kconfig.txt | 有关使用 Linux 内核配置工具的信息。 |
| DocBook/ | 内核里有大量的由内核源码自动生成的文档。 其中包括了内核内部API的全面描述, 和如何处理好锁的规则。 文档格式包括 PDF, Postscritpt, HTML 和 man pages, 可在内核源码主目录下运行下列命令自动生成, 见下文。 |
2.2 配置文件
| Files | Description |
|---|---|
| Kconfig | 内核配置选项文件 Kconfig |
| Kbuild | 内核编译系统 Kbuild 的 Makefile 文件 |
| Makefile | 顶层 Makefile 文件 |
配置文件具体使用方法见《Linux Kernel Programming-A comprehensive guide to kernel internals, writing kernel modules, and kernel synchronization-Packt Publishing (2021) P62》。
2.3 代码文件
| Directory | Description |
|---|---|
| arch/ | 1、与平台相关的代码和头文件:arch/ 包含所有与特定硬件体系相关的内核代码(进程调度、内存管理、中断等);与硬件平台相关的头文件放在 arch/<cpu>/include 目录下。2、与平台不相关的代码和头文件:内核通用代码(与体系无关的代码)存放在 kernel 目录下;与平台无关的内核头文件放在 include/ 目录下。arch 目录下处理器体系架构介绍,参见Appendix E: arch目录下处理器体系架构介绍节。 |
| block/ | 块设备驱动程序核心代码,如 I/O 调度、page cache 等。最初block层的代码一部分位于 drivers/ 目录,一部分位于 fs/ 目录,从2.6.15开始,块设备的核心代码被提取出来放在了顶层的 block/ 目录。 |
| certs/ | 从 Linux 内核版本 3.7 开始,添加了对内核模块签名的支持。启用后,Linux 内核将仅加载使用正确密钥进行数字签名的内核模块。这允许通过禁止加载未签名的内核模块或使用错误密钥签名的内核模块来进一步强化系统。恶意内核模块是在 Linux 系统上加载 rootkit 的常用方法。Refer toSigned Kernel Module Support. |
| crypto/ | 内核本身所用的加密算法代码,实现了常用的加密和散列算法,还有一些压缩和 CRC 校验算法。还向其他驱动提供加密使用的 API。 |
| drivers/ | 包含内核中所有的设备驱动程序,每种驱动程序占用一个子目录,如字符设备、块设备、网络设备、scsi设备驱动程序等。 |
| firmware/ | 使用某些驱动程序而需要的设备固件。 从 v5.0 开始,该文件夹移动到 drivers/base/firmware_loader/builtin/ 下。 |
| fs/ | 包含所有文件系统的代码,每种文件系统占用一个子目录。分为虚拟文件系统(如 proc/sysfs)和独立文件系统(如ext2、ext3、ext4等)。 |
| include/ | 1、包含编译内核代码时所需的大部分头文件。与体系架构无关的头文件包含在include/linux目录下。 2、与硬件平台相关的头文件放在 arch/<cpu>/include 目录下 |
| init/ | 与体系架构无关的内核的初始化和启动的代码,这是内核开始工作的起点。著名的 start_kernel(void) 函数就位于 init/main.c。 |
| ipc/ | 包含进程间通信的代码(包含 SysV 和 POSIX 两种机制)。如消息队列、信号量、共享内存等。 |
| kernel/ | 包含与体系架构无关的的核心代码。与体系架构有关的核心代码包含在 arch/$(ARCH)/kernel/ 目录下。 |
| lib/ | 核心的库代码,主要包含加解压、校验和、bitmap、数学函数、kobject 结构等。与 arch/$(ARCH)/lib 下的代码不同,这里的库代码都是用C编写的,在内核新的移植版本中可以直接使用。这些库代码的地位等同于内核核心代码,内核空间不支持共享库文件(share library,不同于用户空间)。 |
| mm/ | 包含所有与体系架构无关的内存管理代码。与体系架构有关的内存管理代码包含在 arch/$(ARCH)/mm/ 目录下。 |
| net/ | 包含内核sh的网络代码。各种 RFCs 规范常用网络协议的实现代码,如 TCP、UDP、IP 等。 |
| samples/ | Linux内核的示范代码。 |
| scripts/ | 包含内核所用的脚本文件。如用于编译内核、动静态分析脚本等。 |
| security/ | 包括了不同的 Linux 安全模型的代码。例如: NSA Security-Enhanced Linux;Linux Security Module(LSM)如 SELinux 等。 |
| sound/ | 声卡驱动、音频子系统以及其他声音相关设备驱动代码。如 Advanced Linux Sound Architecture(ALSA)。 |
| tools/ | Tools helpful for developing Linux. 目录 tools/perf/ 中包含由内核维护人员Ingo Molnar等人开发的Linux内核综合性能概要分析工具。 |
| usr/ | Early user-space code (called initramfs)。包含 initramfs 的实现代码。 |
| virt/ | 虚拟化相关代码。Hypervisor 和 Kernel Virtual Machine(KVM)的实现代码。 |
与用户空间 API 交互相关的代码主要是系统调用、VFS 虚拟文件系统(/proc, /sys)。
本节参考文件:
- http://chenweixiang.github.io/2019/01/18/linux-kernel-reading.html#2-linux-kernel-
- 《Linux设备驱动开发 1.1.1(袁鹏飞翻译自 Linux Device Driver Development 2017 John Madieu)》
- 《Linux设备驱动开发详解:基于最新的Linux4.0内核 3.3》
- 《Linux驱动程序开发实例(第2版)1.5.2》
- 《Linux Kernel Programming - A comprehensive guide to kernel internals, writing kernel modules, and kernel synchronization-Packt Publishing (2021) P57》
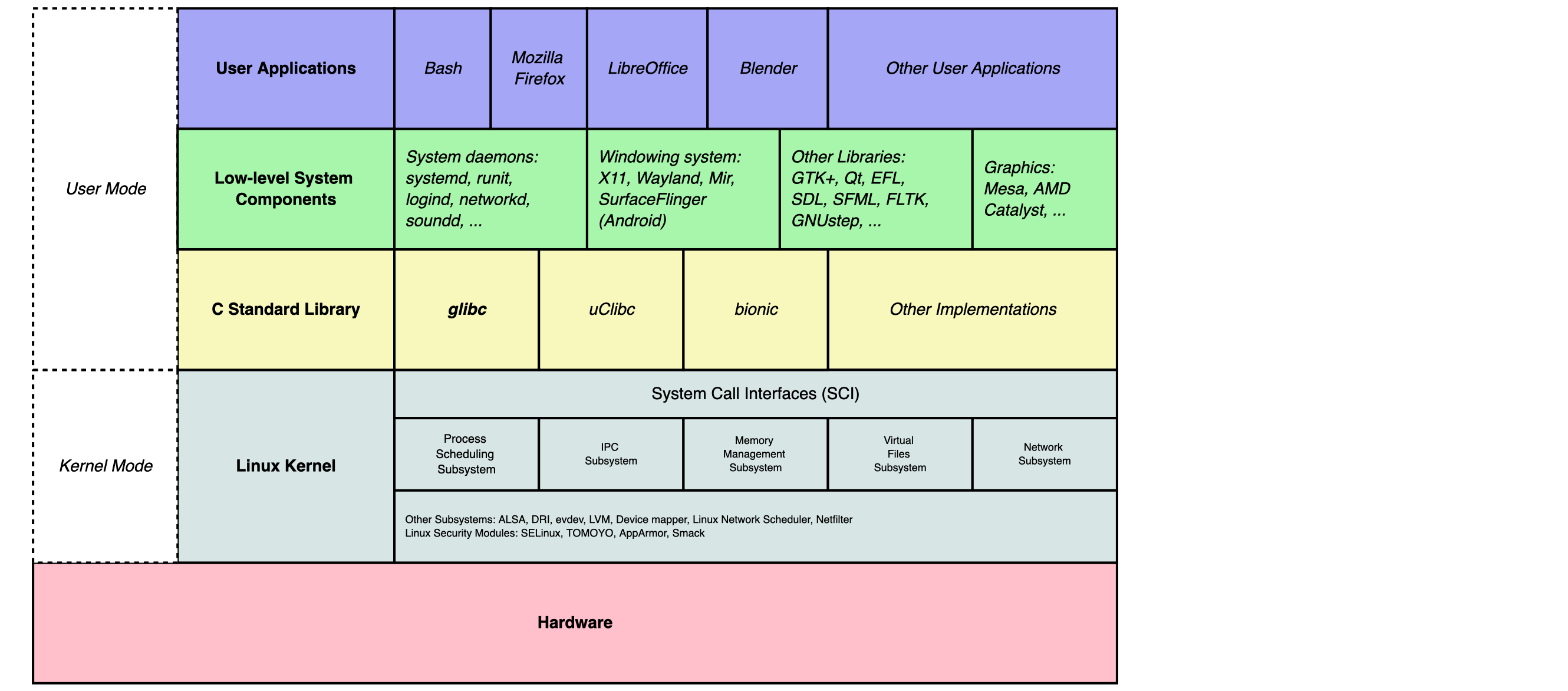
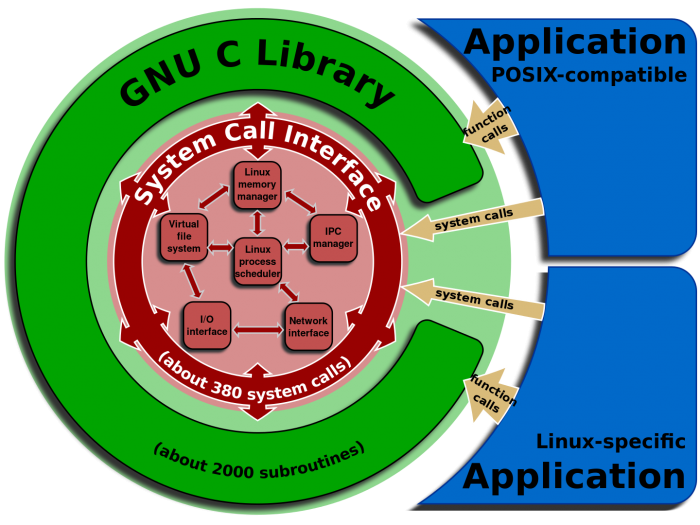
- http://chenweixiang.github.io/2015/12/10/linux-series-01-overview.html
- http://chenweixiang.github.io/2019/01/18/linux-kernel-reading.html#13-loadable-kernel-module
- http://chenweixiang.github.io/2015/12/16/linux-series-04-linux-kernel.html
- http://chenweixiang.github.io/docs/Linux_Device_Drivers.pdf
3 内核特点
Linux 内核由几个主要子系统和几个组件组成。
3.1 Linux 内核子系统
Linux 内核主要由进程调度(SCHED)、内存管理(MM)、虚拟文件系统(VFS)、网络接口(NET)和进程间通信(IPC)5 个子系统组成。
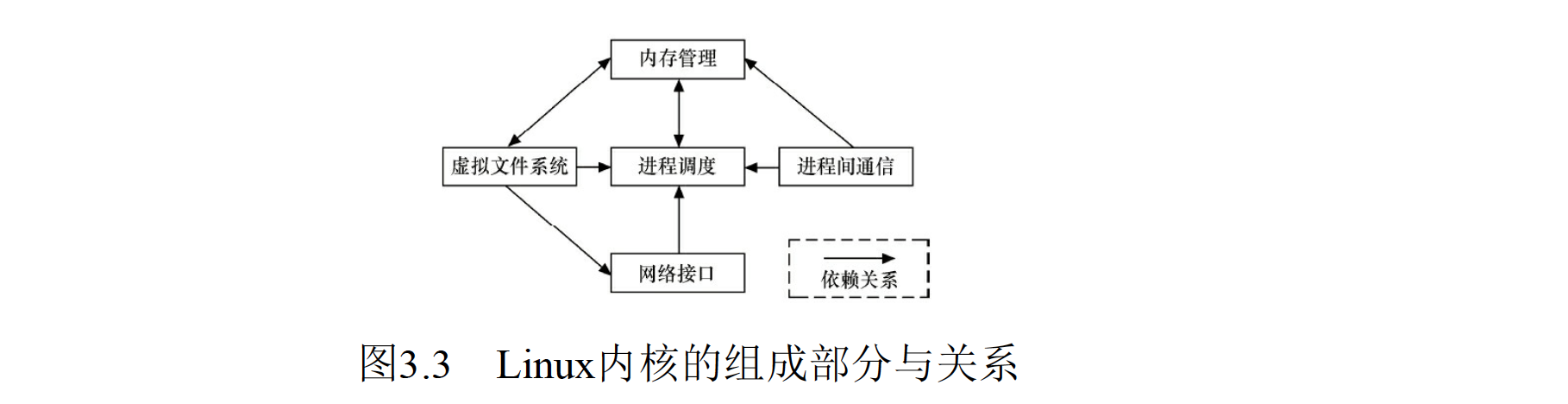
| 子系统 | 描述 |
|---|---|
| 进程调度 | Linux 内核中,使用 task_struct 结构体来描述进程,该结构体中包含描述该进程内存资源、文件系统资源、文件资源、tty 资源、信号处理等的指针。 |
| 内存管理 | CPU 提供内存管理单元(MMU),将每个进程完成从虚拟内存到物理内存的转换。Linux 2.6 引入了对无 MMU CPU 的支持。虚拟地址空间(Virtual Address Spaces,VAS)。 如图 3.6 所示,Linux 内核的内存管理总体比较庞大,包含底层的 Buddy 算法,它用于管理每个页的占用情况,内核空间的 slab 以及用户空间的 C 库的二次管理。另外,内核也提供了页缓存的支持,用内存来缓存磁盘,per-BDI flusher 线程用于刷回脏的页缓存到磁盘。Kswapd(交换进程)则是 Linux 中用于页面回收(包括 file-backed 的页和匿名页)的内核线程,它采用最近最少使用(LRU)算法进行内存回收。  |
| 虚拟文件系统 | Linux 虚拟文件系统隐藏了各种硬件的具体细节,为所有设备提供了统一的接口。而且,它独立于各个具体的文件系统,是对各种文件系统的一个抽象。它为上层的应用程序提供了统一的 vfs_read(), vfs_write() 等接口,并调用具体底层文件系统或者设备驱动中实现的 file_operations 结构体。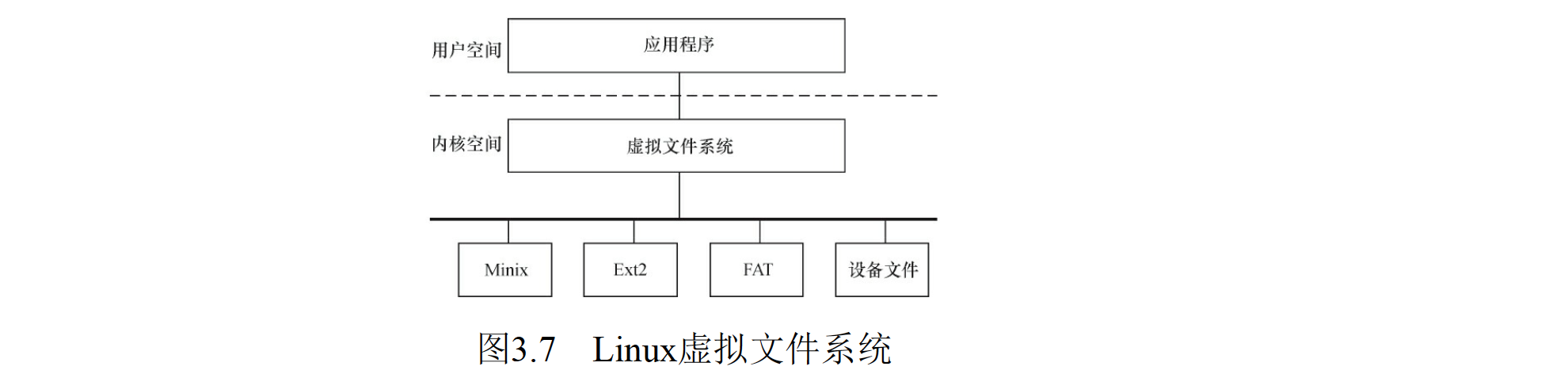 |
| 网络接口 | 网络接口提供了对各种网络标准的存取和各种网络硬件的支持。Linux 以其精确、严格的 RFC,在所有层上高质量地实现众所周知的(和不太知名的)网络协议模型而闻名,其中包括 TCP/IP 也许是最著名的。 在 Linux 中网络接口可分为网络协议和网络驱动程序: - 网络协议部分负责实现每一种可能的网络传输协议; - 网络设备驱动程序负责与硬件设备通信,每一种可能的硬件设备都有相应的设备驱动程序。 上层的应用程序统一使用套接字接口。 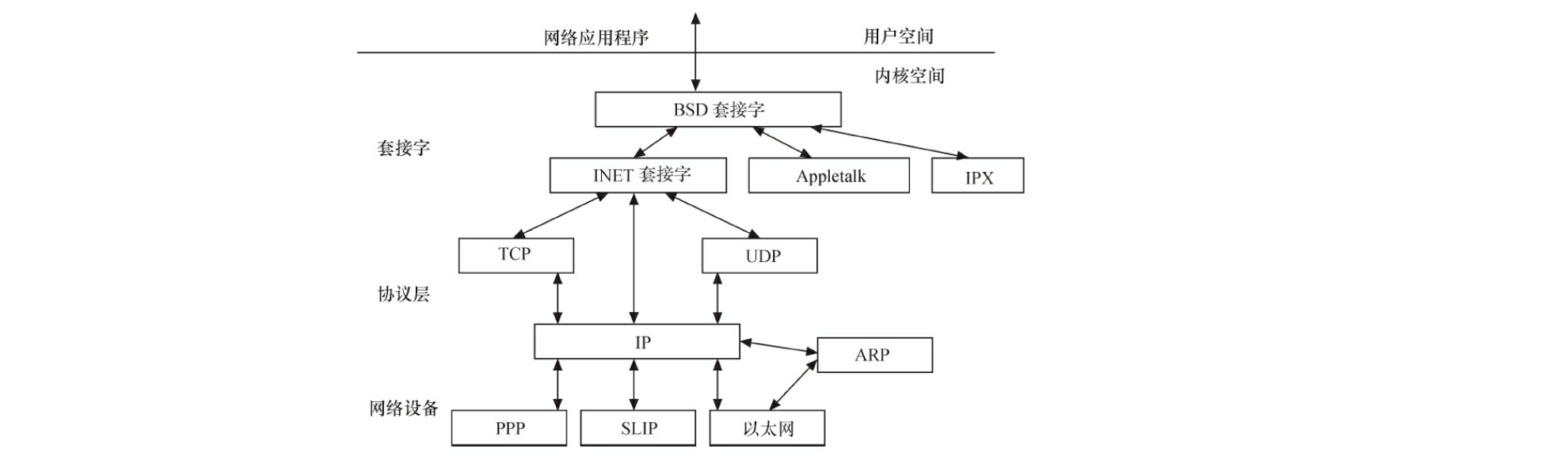 |
| 进程间通信 | Linux 支持进程间的多种通信机制,包含信号量、共享内存、消息队列、管道、UNIX 域套接字等,这些机制可协助多个进程、多资源的互斥访问、进程间的同步和消息传递。 在实际的 Linux 应用中,人们更多地趋向于使用 UNIX 域套接字,而不是 System V IPC 中的消息队列等机制。 |
其他重要组件:
- 核心内核(Core kernel):此代码处理现代操作系统的典型核心工作,包括(用户和内核)进程和线程创建/销毁、CPU 调度、同步原语、信号发送、计时器、中断处理、命名空间、cgroups、模块支持、加密等等。
- 块 I/O(Block IO):实现实际文件 I/O 的代码路径,从 VFS 一直到块设备驱动程序以及中间的所有内容(真的,相当多!),都包含在这里。
- 音频支持(Sound support):所有实现音频的代码都在这里,从固件到驱动程序和编解码器。
- 虚拟化支持(Virtualization support):Linux 在大大小小的云提供商中都非常受欢迎,一个重要原因是其高质量、低占用空间的虚拟化引擎、基于内核的虚拟机(Kernel-based Virtual Machine,KVM)。
内核中的所有子系统还要依赖于一些共同的资源。这些资源包括所有子系统都用到的 API,如分配和释放内存空间的函数、输出警告或错误消息的函数及系统提供的调试接口等。
Monolithic kernel(宏内核)与 Microkernel(微内核):
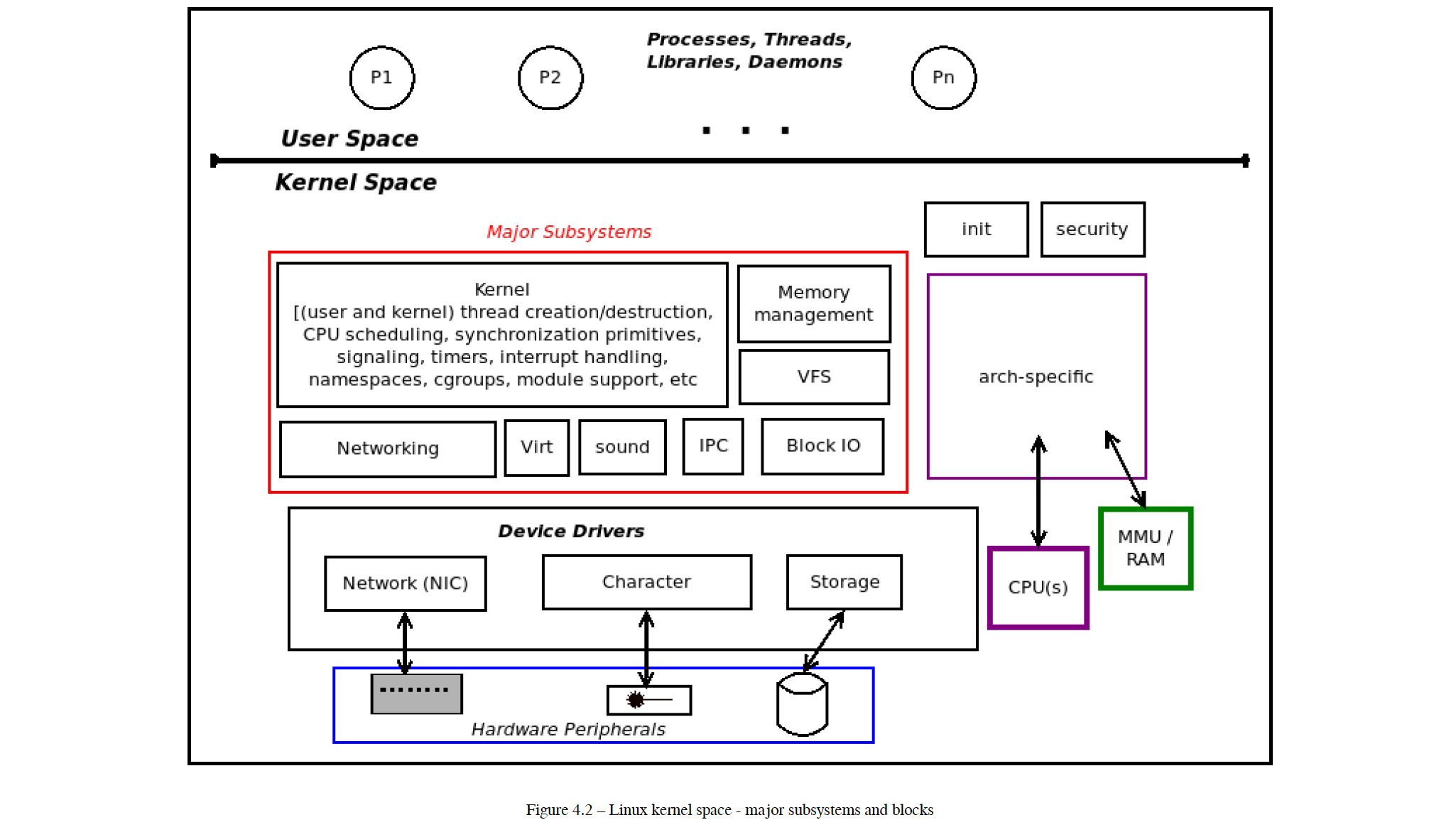
- 宏内核:所有的内核子系统(例如文件系统,内存分配,调度器,虚拟内存系统)都是集成在一个非常大的进程中。Linux 内核是 Monolithic kernel。It is a well-known fact that the Linux kernel follows the monolithic kernel architecture. Essentially, a monolithic design is one in which all kernel components (that we mentioned in this section) live in and share the kernel address space (or kernel segment). This can be clearly seen in Figure 4.2.——《Linux Kernel Programming》。
- 微内核:将单个功能或模块从宏内核中解耦拆分出来,如文件系统、图像子系统功能放到单独的内核模块中。内核进程质只保留最基本的 CPU 调度、内存管理和进程通信等功能。Windows 内核是 Microkernel。
本节参考内容:
- 《Linux设备驱动开发详解:基于最新的Linux4.0内核 3.3.2》
- 《Linux Kernel Programming - A comprehensive guide to kernel internals, writing kernel modules, and kernel synchronization-Packt Publishing (2021) P147》
3.2 内核 2.6 之后的变化
内核的内容是不断在扩充的,本节参考《Linux设备驱动开发详解:基于最新的Linux4.0内核 3.1》针对 Linux 2.6 之后的变化进行总结,并在后续的学习中,将学习到的内核新的变化补充在本节之后。
Linux 2.6 较 Linux 2.4 的变化:
| 变化 | 描述 |
|---|---|
| 进程调度算法 | Linux 2.6 以后版本的内核使用了新的进程调度算法,它在高负载的情况下有极其出色的性能,并且当有很多处理器时也可以很好地扩展。在 Linux 内核 2.6 的早期采用了O(1) 算法,之后转移了 CFS(Completely Fair Scheduler,完全公平调度)算法。在 Linux 3.14中,也增加了一个新的调度类: SCHED_DEADLINE,它实现了 EDF ( Earliest Deadline First, 最早截止期限优先)调度算法。 |
| 内核抢占 | Linux 2.6 以后版本的 Linux 内核中,一个内核任务可以被抢占,从而提高系统的实时性。但还是存在一些不可抢占的区间,如中断上下文,软中断上下文和自旋锁锁住的区间,如果给 Linux 内核打上 RT-Preempt 补丁,则中断和软中断都被线程化了,自旋锁也被互斥体替换,Linux 内核变得能支持硬实时。 也就是说,Linux 2.6 以后的内核仍然存在中断、软中断、自旋锁等原子上下文进程无法抢占执行的情况,这是 Linux 内核本身只提供软实时能力的原因。 |
| 改进的线程模型 | Linux 2.6 以后版本中的线程采用 NPTL (Native POSIX Thread Library,本地 POSIX 线程库)模型,操作速度得以极大提高,相比于 Linux 2.4 内核时代的 LinuxThreads 模型,它也更加遵循 POSIX 规范的要求。 NPTL 没有使用 LinuxThreads 模型中采用的管理线程,内核本身也增加了 FUTEX(Fast Userspace Mutex,快速用户态互斥体),从而减小多线程的通信开销。 |
| 虚拟内存的变化 | 从虚拟内存的角度来看,新内核融合了 r-map(反向映射)技术,显著改善虚拟内存在一定大小负载下的性能。 在 Linux 2.4 中,要回收页时,内核的做法是遊历每个进程的所有 PTE 以判断该 PTE 是否与该页建立了映射,如果建立了,则取消该映射,最后无 PTE 与该页相关联后才回收该页。在 Linux 2.6 后,则建立反向映射,可以通过页结构体快速寻找到页面的映射。 |
| 文件系统 | Linux 2.6 版内核增加了对日志文件系统功能的支持,解决了 Linux 2.4 版本在这方面的不足。Linux 2.6 版内核在文件系统上的关键变化还包括对扩展属性及 POSIX 标准访问控制的支持。ext2/ext3/ext4 作为大多数 Linux 系统默认安装的文件系统,在 Linux 2.6 版内核中增加了对扩展属性的支持,可以给指定的文件在文件系统中嵌入元数据。 在文件系统方面,当前的研究热点是基于 B 树的 Btrfs,Btrfs 称为是下一代 Linux 文件系统,它在扩展性、数据一致性、多设备管理和针对 SSD 的优化等方面都优于 ext4。 |
| 音频 | 高级 Linux 音频体系结构(Advanced Linux Sound Architecture, ALSA)取代了缺陷很多旧的 OSS(Open Sound System)。ALSA 支持 USB 音频和 MIDI 设备,并支持全双工重放等功能。 |
| 总线、设备和驱动模型 | 在 Linux 2.6 以后的内核中,总线、设备、驱动三者之间因为一定的联系性而实现对设备的控制。 总线是三者联系起来的基础,通过一种总线类型,将设备和驱动联系起来。总线类型中的 match() 函数用来匹配设备和驱动,当匹配操作完成之后就会执行驱动程序中的 probe() 函数。 |
| 电源管理 | 支持高级配置和电源接口(Advanced Configuration and Power Interface, ACPI),用于调整 CPU 在不同的负载下工作于不同的时钟频率以降低功耗。目前,Linux 内核的电源管理(PM)相对比较完善了,包括 CPUFreq、 CPUIdle、CPU 热插拔、设备运行时(runtime)PM、Linux 系统挂起到内存和挂起到硬盘等全套的支持,在 ARM 上的支持也较完备。 |
| 联网和IPSec | Linux 2.6 内核中加入了对 IPSec 的支持,删除了原来内核内置的 HTTP 服务器 khttpd,加入了对新的 NFSv4(网络文件系统)客户机/服务器的支持,并改进了对 IPv6 的支持。 |
| 用户界面层 | Linux 2.6 内核重写了帧缓冲/控制台层,人机界面层还加入了对近乎所有接口设备的支持(从触摸屏到盲人用的设备和各种各样的鼠标) |
| 设备驱动程序 | Linux 2.6 相对于 Linux 2.4 有较大的改动,这主要表现在内核 API 中增加了不少新功能(例如内存池)、sysks 文件系统、内核模块从 .o 变为 .ko、驱动模块编译方式、模块使用计数、模块加载和卸载函数的定义等方面。 |
4 内核开发编程基础
4.1 编码风格
Linux 内核开发编码风格和 Windows 内核开发编码风格有着很大的差别,Linux 内核中详细的编码格式可以在内核源代码树 Documentation/CodeStyle 文件中进行查看。scripts/checkpatch.pl 可以用于检查目标代码文件是否有格式错误。
更多关于 Linux 编码风格中文文档可参考:《Linux 内核代码风格》。
一、Windows 编码风格
- 函数:所有单词首字母大写
- 宏:全部大写
- 变量:第一个单词全小写,其后单词首字母大写
1 |
|
二、Linux 编码风格
| 类型 | 说明 |
|---|---|
| 函数、变量 | 全部小写,单词之间使用下划线 _ 分割。 |
| 宏 | 全部大写 |
| 缩进与行长 | 缩进:使用 Tab 键,相当于 8 个空格(不是 4 个)。如果缩进妨碍书写,那只能说明嵌套层次太多了。行长:每一行不超过 80 个字符。 可以使用内核源码数中 scripts/cleanfile 脚本设置目标代码文件制表符大小和行长度:scripts/cleanfile tagrt_module.c。也可以使用 intent 工具对目标代码文件进行正确缩进:scripts/Lindent tagrt_module.c。 |
| 非导出函数、变量 | 每一个不被导出的函数或者变量都必须生命为静态的,使用 static 关键字。 |
| 注释 | 使用 /* this is well */(C98 风格),不要使用 //(C99 风格)。for 中不要定义变量,如 for(int i = 0; i < 1; i++) 不被允许(C99 可定义)。 |
| 括号内部两端不要添加空格 | 可接受:s = sizeof(struct file)不接受: s = sizeof( struct file ) |
| typedef | 禁止使用 typedef。 |
| { } 大括号 | (1)结构体、if, for, while, switch 语句,{ 无需单独另起一行,} 要和前述关键字对齐;(2)函数, { 需要另起一行;(3)如果 if, for 循环语句只有 1 行,则无需使用 { };(4) if 与 else 搭配使用时,else 语句无需另起一行,直接跟在 if 的 } 后面; |
| switch/case | case 与 switch 对齐。 |
| 空格 | (1)一般在 = 前后使用空格;(2)代码语句中,在 , 或 for 语句的 ; 后使用空格;(3)在 ( 或 { 前使用空格(不强制) |
| 浮点计算 | 许多体系结构下的 Linux 内核中,并不支持浮点数的计算,因此需要想办法使用整数来代替。在内核中应尽量避免使用浮点数。 |
4.2 GNU C 扩展
GNU C 编译器是 Linux 上可用的 C 编译器,对标准 C 进行了一系列扩展,以增强标准 C 的功能。bootlin-Glibc 在线源码。
导航:
| 分类 | 分类 | 分类 | 分类 | 分类 |
|---|---|---|---|---|
| 1、零长度数组 | 2、case x…y 语法 | 3、语句表达式 | 4、typeof 关键字 | 5、可变参数宏 |
| 6、结构体初始化 | 7、当前函数名 | 8、特殊属性声明 __attribute__ | 9、内建函数 __builtin | 10、语句表达式与 do{}while(0) 的区别 |
使用 GCC 编译器编译程序时,默认是开启 GCC 扩展的,可以使用使用 -ansi-pedantic 编译选项,则会告诉编译器不使用 GNU 扩展,使用该编译选项时,如果代码中使用了 GCC 扩展的特性则会报错,不建议使用该编译选项。
一、零长度数组
0 长度的数组(也叫变长数组、柔性数组)经常用于结构体的最后一个成员,且数组前必须含有至少一个其他成员。为了满足需要变长度的结构体。
编译后,该成员并不占用空间,如下 sizeof(struct var_data) == sizeof(int),注意结构体数据对齐单位是 4 bytes。
1 | struct var_data{ |
使用方法如下:
1 | struct var_data* pdata = NULL; |
当然,C99 之后添加了变长数组的支持,只不过格式如下(使用 data[]):
1 | struct var_data{ |
更多内容可参阅C语言0长度数组(可变数组/柔性数组)详解。
二、case x...y 语法
case x...y:表示 [x, y] 区间的数都满足这个 case 条件。(每个 case 后无需使用 { },遇到 break 会自动结束)。
请注意:如果 case 范围的一个端点是数值,则在省略号(...)两侧留空格以避免其中一个点被视为小数点。建议 ... 两侧都加空格。
1 | switch(c) { |
三、语句表达式
GNU C 把包含在括号中的复合语句看成是一个表达式,称为语句表达式,它可以出现在任何允许表达式的地方。语句表达式的作用:返回最后一个语句的值。
正常的符合语句会放到一个大括号
{ }中,如常见的if, while后面的大括号就是复合语句。如果将一个大括号中的代码放到( )里面,就成了表达式(语句表达式)。
语句表达式的格式:
1 | ({ |
使用方法如下:
1 | /* 注意最后一句有分号 */ |
上面的实例如果不使用语句表达式,最后一行代码不能使用分号:
1 | /* 如果不使用语句表达式,最后一行代码不能使用分号 */ |
语句表达式的作用:不会产生使用宏定义时带来的副作用(side effect)。
宏定义:一般不会在最后使用 ;,否则在后续代码中使用时原样展开会产生错误。
上面宏函数 max 副作用举例:max(++a, ++b) 展开会变成 ++x < ++y ? ++y : ++x。
四、typeof 关键字
typeof() 是 GUN C 提供的一种扩展特性,可参考 C-Extensions,它可以取得变量的类型,或者表达式的类型。标准 C++ 在头文件 <typeinfo.h> 有类似的 __typeof 函数(标准 C 中没有)。
举例,使用 typeof 关键字修改上面 min_t 宏,这样就无需传入 type 参数了:
1 |
|
使用如下:
1 |
|
五、可变参数宏
标准 C 就支持可变参数函数,意味着函数的参数是不固定的,例如 printf() 函数的原型为:
1 | int printf(const char *format [, argument]...); |
而在 GNU C中,宏也可以接受可变数目的参数,例如:
1 |
- 这里
arg表示其余的参数,可以有零个或多个参数,这些参数以及参数之间的逗号构成arg的值; - 使用
##是为了处理arg不代表任何参数的情况,这时候,前面的逗号就变得多余了。使用##之后, GNU C 预处理器会丢弃前面的逗号。
六、结构体初始化
标准 C 要求数组或结构体的初始化值必须以固定的顺序出现,在 GNUC 中,通过指定索引或结构体成员名,允许初始化值以任意顺序出现。
1 | struct file_operations ext2_file_operations = { |
但是,Linux 2.6 推荐类似的代码应该尽量采用标准 C 的方式:
1 | struct file_operations ext2_file_operations = { |
七、当前函数名
GNU C 预定义了两个标识符保存当前函数的名字,__FUNCTION__ 保存源码中函数名字符串, __PRETTY_FUNCTION__ 可以得到函数的名称字符串以及对应的参数。在 C 函数中,这两个名字是相同的。
注意:C99 已经支持 __func__ 宏,因此建议在 Linux 编程中不再使用 __FUNCTION__ ,而转而使用 __func__:
1 |
|
八、特殊属性声明 __attribute__
__attribute__ 不是 C 的一部分,而是 GCC 中的扩展,用于向编译器传达特殊信息。
GNU C 允许声明函数、变量、类型、标签(label)、枚举(enum)、语句的特殊属性,以便手动优化代码和定制代码检查的方法。官方文档 Attribute Syntax (Using the GNU Compiler Collection (GCC))。
使用格式(可参考属性的语法 Attribute Syntax):
(1)要指定一个声明的属性,只需要在声明后添加 __attribute__((option)),但是必须在 ; 前 ;
(2)括号里的 option 为可选的属性(关于括号,请写两遍。 如果只有一个,就会发生错误。);
(3)如果存在多个属性,则以逗号分隔;
(4)还可以可选的属性前后加上双下划线 __,如 __noreturn__。
函数:可以在定义函数时写在函数前,也可以在声明函数时写在函数后。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/* 方式一 */
void end(void) __attribute__((destructor));
void end(void)
{
system("leaks pipex");
}
/* 方式二 */
__attribute__((destructor)) void end(void)
{
system("leaks pipex");
}
/* 定义变量 */
const int identifier[3] __attribute__ ((section ("ident"))) = { 1,2,3 };变量、类型、标签(label)、枚举(enum)、语句:
__attribute__放最最后。
__attribute__((option)) 的 option,用于声明函数、变量、类型、标签(label)、枚举(enum)、语句等,主要有架构通用属性和基于不同架构平台的属性。比如举个例子,常见的通用(Common)函数属性:constructor, destructor, used, noinline 等;而在不同架构下编程时,还有特定架构中才能使用的属性,如 naked, interrupt 等,具体的可以看 __attribute__。
| 属性名称 | 作用域(F:函数, V: 变量,T: 类型) | 含义 | 备注 |
|---|---|---|---|
constructor |
F |
使被修饰的函数在 main 函数前被执行 | |
destructor |
F |
使被修饰的函数在 main 函数结束后被执行 | |
format |
F |
告诉编译器,按照 printf, scanf, strftime 或 strfmon 的参数表格式规则对该函数的参数进行检查 | |
noreturn |
F |
此属性告诉编译器该函数永远不会返回,这可用于抑制有关未到达代码路径的错误。 C 库函数 abort() 和 exit() 均使用此属性声明。 | |
regparm(n) |
F |
指定函数被调用时,仅有 n 个参数通过寄存器传递,其余参数使用堆栈传递。 |
|
const |
F |
表示一个方法的返回值只由参数决定,如果参数不变的话,就不再调用此函数,直接返回值 | |
weak |
F |
弱函数,如果同名函数在其他地方被定义将使用其他地方的函数,当其他地方没有定义才使用该函数 | |
section("name") |
FV |
在编译时将被修饰的函数或数据放入指定名为”name”对应的段中 | 需要修改链接脚本才能生效 |
aligned(n) |
VT |
指定变量、结构体或联合体的对齐方式,以字节为单位,不指定数字时,编译器自动选择对目标机器最优方式。 如果 aligned 后面不紧跟着一个指定的数字值,那么编译器将依据你的目标机器状况使用最大、最有益的对齐方式。 |
|
nothrow |
F |
属性告诉编译器函数不能抛出异常(当代码会被C++调用时才使用) | |
packed |
VT |
告诉编译器取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐 用于变量或结构体成员时表示使用最小可能的对齐,用于枚举、结构体或联合体类型时表示该类型使用最小的内存。 |
|
used |
V |
用于静态变量。指示编译器优化时,即使该变量没有被引用,也必须保留该变量。否则在静态链接的时候链接器发现某个变数未被引用,会将此变数优化掉。 | |
unsed |
FV |
表示该函数或变量可能不会用到,这个属性可以避免编译器产生警告信息。 | |
pure |
F |
函数除返回值外,不会通过其它(如全局变量、指针)对函数外部产生任何影响。 | |
nonull(n) |
F |
函数第n个参数不能为NULL |
多个参数时使用逗号隔开 |
naked |
F |
裸函数,指定编译器生成汇编代码时不生成 prologue/epilogue 部分,即开辟堆栈和最后堆栈平衡处理的代码。主要用在 ARM, AVR, MCORE, RX 等架构上。 | |
| … |
关于 naked 属性可参考:gcc 属性 attribute((naked)) 使用场景。
九、内建函数 __builtin
GNU C 提供了大量内建函数,其中大部分是标准 C 库函数的 GNU C 编译器内建版本,例如 memepy() 等,它们与对应的标准 C 库函数功能相同。__builtin 函数是一种在编译器内部实现的,使用它并不需要包含 #include<> 头文件的支持。bootlin-Glibc 在线源码。
不属于库函数的其他内建函数的命名通常以 __builtin 开始,如:
内建函数
__builtin_return_address(LEVEL)返回当前函数或其调用者的返回地址,参数LEVEL指定调用栈的级数,如0表示当前函数的返回地址,1表示当前函数的调用者的返回地址。内建函数
__builtin_constant_p(EXP)用于判断一个值是否为编译时常数,如果参数EXP的值是常数,函数返回1,否则返回0。内建函数
__builtin_expect(long EXP, long C)用于为编译器提供分支预测信息,其返回值是整数表达式EXP的值,C 的值必须是编译时常数。Linux 内核编程时常用的likely()和unlikely()底层调用的likely_notrace(), unlikely_notrace()就是基于__builtin_expect(EXP, C)实现的。1
2
3
4
5
6
7
8/* include/linux/compiler.h */
...
更多内容可以参考:
十、语句表达式与 do{}while(0) 的区别
语句表达式的作用:返回最后一个语句的值,具有返回的功能。
如下代码,会返回最后一句代码的计算结果:
1
2
3
4
5
6
({ \
typeof(x) m = x; \
typeof(y) n = y; \
m < n ? m : n; \
})do{}while(0)用在宏中的作用:可将多个代码语句集合在do{}里面,并且可以像正常写代码一样在do{}里面使用分号;。如下代码:
1
2
3
4
5
INIT_LIST_HEAD(&car->list); \
(car)->number = i + 1; \
(car)->people = i + 2; \
}while(0)
4.3 likely 与 unlikely
现代 CPU 具有众多启发式分支预测法,它尝试着预测即将到来的命令,以便达到最快的速度。宏 likely() 和 unlikely() 允许开发者通过编译器告诉 CPU:某一代码段很可能被执行,因而应该被预测到; 某一代码段很可能不被执行,不必预测。
注意:likely() 和 unlikely() 是两个宏,这两个宏都是通过 __builtin_expect(long EXP, long C) 来实现的。编译时需要至少使用 -O2 选项,否则优化不起作用。
目的:代码中使用 likely() 和 unlikely() 这两个宏主要目的提高 CPU 分支预测命中率。所以这两个宏经常用在有分支跳转的地方,如 if() 等被编译后有 jcc 的地方。
先说结论:
likely 和 unlikely 都不会改变程序的执行结果,他们结果上和 if() 原意一样,只不过编译器编译生成的汇编指令在遇到 jcc 时会有所不同。
likely(x)等价于 x,即if(likely(x))等价于if(x),但是它告诉 gcc,x取1的可能性比较大。unlikely(x)等价于x,即if(unlikely(x))等价于if(x),但是它告诉 gcc,x取0的可能性比较大。- 使用
likely()则执行if后面的语句的机会更大,使用unlikely()则执行else后面的语句机会更大一些。 - 使用
likely()则编译器会让 CPU 预取的指令是if中的,jcc跳转目的的指令是else。 - 使用
unlikely()则编译器会让 CPU 预取的指令是else中的,jcc跳转目的的指令是if。
1 | /* include/linux/compiler.h */ |
likely(x) 宏传入 __builtin_expect(!!(x), 1) 的第一个参数为 !!x 运算,这样写是因为 __builtin_expect 的第一个参数需要为 long 型,而我们如果想传入指针或字符串类型,则需要使用!!x将x变成long型,例如,如果一个指针ptr==NULL,则!ptr=1,而!!ptr=0。
举例:
使用
likely()。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int main(int argc, char* argv[], char* envp)
{
if(__builtin_expect(!!(argc > 0), 1)) // likely()
{
printf("[*] argc > 0\n");
}else
{
printf("[*] argc <= 0\n");
}
return 0;
}
/* 输出 */
[*] argc > 0使用 GCC 编译(开启 3 级优化):
1
gcc -O3 -w -fPIC -o 1217_likely.exe 1217_likely.c
反编译的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22.text:0000000000400440 // int __cdecl main(int argc, const char **argv, const char **envp)
.text:0000000000400440 public main
.text:0000000000400440 main proc near
.text:0000000000400440 // __unwind {
.text:0000000000400440 sub rsp, 8
.text:0000000000400444 test edi, edi
.text:0000000000400446 jle short loc_40045B
.text:0000000000400448 lea rdi, s // "[*] argc > 0"
.text:000000000040044F call _puts
.text:0000000000400454
.text:0000000000400454 loc_400454: // CODE XREF: main+27↓j
.text:0000000000400454 xor eax, eax
.text:0000000000400456 add rsp, 8
.text:000000000040045A retn
.text:000000000040045B // ---------------------------------------------------------------------------
.text:000000000040045B
.text:000000000040045B loc_40045B: // CODE XREF: main+6↑j
.text:000000000040045B lea rdi, aArgc0_0 // "[*] argc <= 0"
.text:0000000000400462 call _puts
.text:0000000000400467 jmp short loc_400454
.text:0000000000400467 // } starts at 400440
.text:0000000000400467 main endp可以看到,第一个
jcc是else中的内容:jle short loc_40045B,然后 CPU 预取的内容是lea rdi, s // "[*] argc > 0"。即 CPU 流水线在遇到jcc指令所代表的的’岔路口’时,更倾向于走if分支。使用
unlikely()。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int main(int argc, char* argv[], char* envp)
{
if(__builtin_expect(!!(argc > 0), 0)) // unlikely()
{
printf("[*] argc > 0\n");
}else
{
printf("[*] argc <= 0\n");
}
return 0;
}
/* 输出 */
[*] argc > 0同样使用
-O3开启 3 级优化编译,反汇编如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22.text:0000000000400440 // int __cdecl main(int argc, const char **argv, const char **envp)
.text:0000000000400440 public main
.text:0000000000400440 main proc near // DATA XREF: _start+1D↓o
.text:0000000000400440 // __unwind {
.text:0000000000400440 sub rsp, 8
.text:0000000000400444 test edi, edi
.text:0000000000400446 jg short loc_40045B
.text:0000000000400448 lea rdi, s // "[*] argc <= 0"
.text:000000000040044F call _puts
.text:0000000000400454
.text:0000000000400454 loc_400454: // CODE XREF: main+27↓j
.text:0000000000400454 xor eax, eax
.text:0000000000400456 add rsp, 8
.text:000000000040045A retn
.text:000000000040045B // ---------------------------------------------------------------------------
.text:000000000040045B
.text:000000000040045B loc_40045B: // CODE XREF: main+6↑j
.text:000000000040045B lea rdi, aArgc0_0 // "[*] argc > 0"
.text:0000000000400462 call _puts
.text:0000000000400467 jmp short loc_400454
.text:0000000000400467 // } starts at 400440
.text:0000000000400467 main endp可以看到,第一个
jcc是if中的内容:jg short loc_40045B,然后 CPU 预取的内容是lea rdi, s // "[*] argc <= 0"。即 CPU 流水线在遇到jcc指令所代表的的’岔路口’时,更倾向于走else分支。
4.4 do{ }while(0) 语句
do{ }while(0) 语句只会执行一次,但是却非常有用,主要用于宏定义中。使用方法类似于语句表达式 ({ })。
举例说明:
1 |
|
如果使用简单的宏进行替换,效果如下:
1 |
|
如果使用 do{ }while(0) 语句,展开情况如下,这样就不会出现编译错误。
1 | static void safe_free() |
结论:do{ }while(0) 的使用完全是为了保证宏定义的使用者正确使用宏。此外,使用 do{ }while(0) 语句的地方也可以改为使用语句表达式 ({ })。
以下使用 do{}while(0) 和语句表达式 ({ }) 是等价的:
1 |
|
4.5 常见数据结构
| 分类 | 分类 | 分类 | 分类 | 分类 |
|---|---|---|---|---|
| 双向链表 list_head | 树与二叉树 |
一、双向链表
Linux 内核自己实现了双向链表,在 include/linux/types.h 中进行定义,对双链表增删改查的函数或宏定义在 include/linux/list.h 中。
导航:
| 分类 | 分类 | 分类 | 分类 | 分类 |
|---|---|---|---|---|
| 1、创建和初始化双向链表 | 2、节点插入 | 3、节点删除 | 4、节点修改 | 5、节点遍历(查询) |
| 6、双向链表注意事项 |
双向链表的结构体类型为 list_head:
1 | struct list_head { |
next表示下一节点;prev表示前一个节点。
双向链表结构体 list_head 一般会嵌入到目标结构体中进行使用,如下:
1 | struct car_club { |
创建和初始化双向链表
动态方法:使用
INIT_LIST_HEAD函数,让链表的next和prev都指向它本身,即创建空链表。1
2
3
4
5
6
7
8
9
10
11/**
* INIT_LIST_HEAD - Initialize a list_head structure
* @list: list_head structure to be initialized.
*
* Initializes the list_head to point to itself. If it is a list header, the result is an empty list.
*/
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}静态方法:使用
LIST_HEAD()宏函数。1
2
3
4
struct list_head name = LIST_HEAD_INIT(name)它扩展开来实际上就是定义了一个
list_head类型的变量name,然后使用宏LIST_HEAD_INIT进行初始化,这会使用变量name的地址来填充prev和next结构体的两个变量。
需要注意:函数
INIT_LIST_HEAD和宏LIST_HEAD传递的参数类型不同,前者是链表的地址,后者是链表本身:1
2
3
4
5struct list_head mylist;
/* 以下两种方法等价 */
INIT_LIST_HEAD(&mylist); /* 函数,更常用 */
LIST_HEAD(mylist); /* 宏,(实际上C语言中 mylist 和 mylist->next 相等) */
节点插入
将节点插入到指定节点之后。使用
list_add函数。1
2
3
4
5
6
7
8
9
10
11
12/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}new:要插入的新节点;head:新节点插入到指定的head节点之后。可以看到,在该函数中调用了内部函数
__list_add:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}可以看到,在
prev和next之间添加了一个新项。将节点插入到指定节点之前。使用
list_add_tail函数。1
2
3
4
5
6
7
8
9
10
11
12/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
节点删除
删除指定节点,使用 list_del 函数。
1 | /** |
节点修改。
修改一个节点,可以使用 list_replace、list_replace_init 等函数,更多函数可以参见 include/linux/list.h。
1 | /** |
节点遍历(查询)。
查找某个节点,可以使用 list_for_each_entry 宏。
1 | /** |
pos:用于迭代的循环游标,它的类型与双向链表所在结构体类型相同。head:双向链表的头结点的地址。member:结构体中双向链表成员的名字。
在使用上,将 list_for_each_entry 当做一个 for() 来使用:
1 | list_for_each_entry() |
使用方法如下:
1 |
|
方法二:单独定义出一个双向链表,来作为头结点,该节点并不会嵌入到任何结构体中。
1 |
|
六、双向链表注意事项
结构体
struct list_head head中 ,如果成员全部都是链表结构,则在程序中可以使用如head->next->prev = list,两个->。结构体
struct NODE node中,如果struct list_head list结构体只是其中一个成员,则只能使用node->list.next = &head,后面使用.而不是->。并且注意:不应该在代码中使用 node->list 这种中间结构(该用法危害极大),应使用node->list.next, node->list.prev, &node->list三个中的一个。关于结构体中,双向链表成员的输出,应该使用如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14/* 以下两种方式等价 */
long ltemp = *(long*)(&(node->list.next));
printf("%llx\n", ltemp);
/* 方式 2 */
printf("%llx\n", node->list.next);
/* 注意不要使用中间结构 */
struct NODE{
long num;
struct list_head list;
};
struct NODE node;
=>>>> 不要使用 node.list <<<<=
4.6 常见宏
导航:
| 分类 | 分类 | 分类 | 分类 | 分类 |
|---|---|---|---|---|
| container_of |
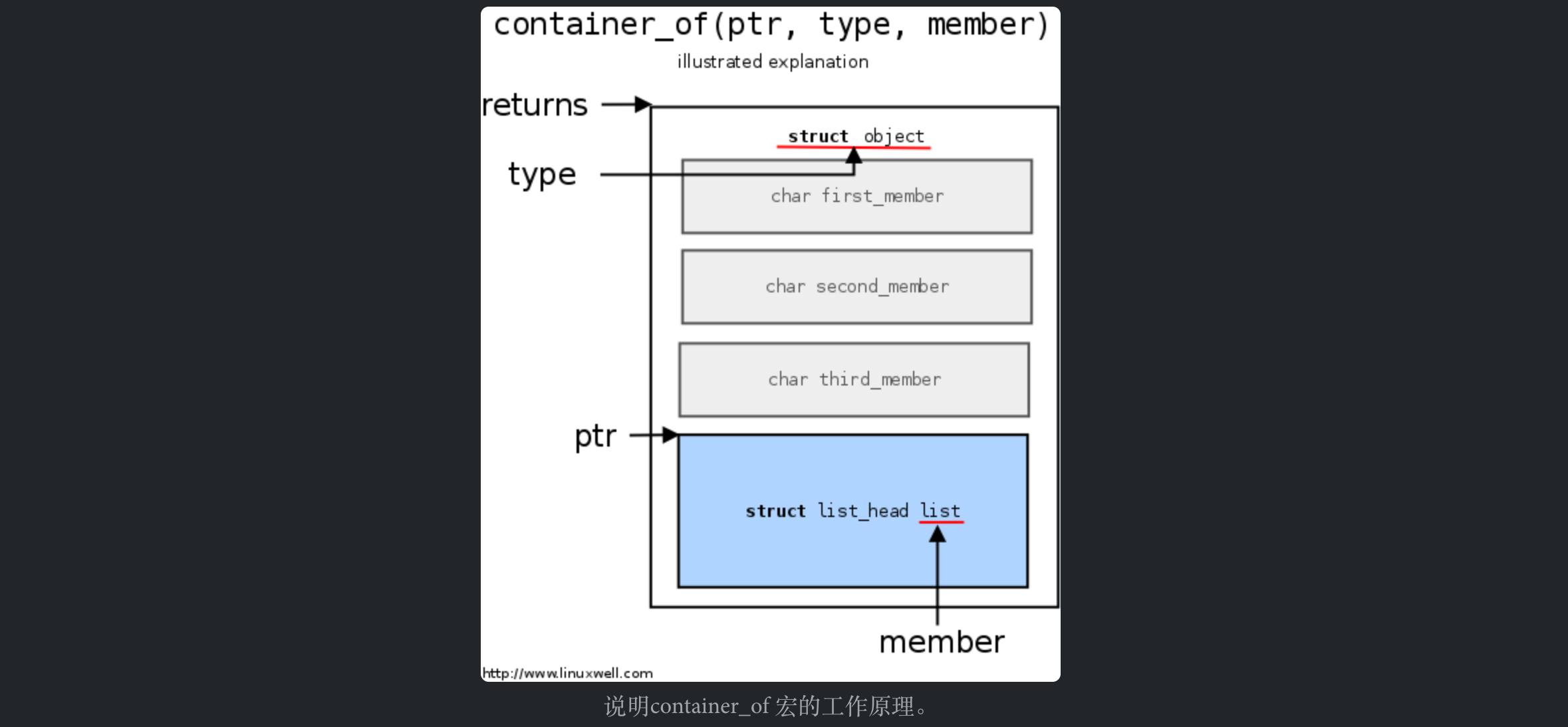
一、container_of 宏
container_of 宏,用来返回指定结构体的基地址,作用同 Windows 内核中使用的 CONTAINING_RECORD 宏,FIELD_OFFSET。
定义在 include/linux/kernel.h 中:
1 |
|
ptr:是一个指针,指向member参数的指针。type:目标结构体的类型。member:目标结构体中的一个成员。
要看懂这个宏,得先弄清楚 (struct st*)0、offsetof() 、typeof 的作用。
typeof:是 GCC 的扩展,它可以取得变量的类型,或者表达式的类型(见章节 4.2)。(struct st*)0:作用实际上就是用来计算偏移量(求成员 member 到该结构体起始指针的字节偏移长度),如下例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
struct st{
int a;
int b;
};
void main(void)
{
if(struct st* s = (struct st*)malloc(0x10))
{
memcpy((char*)s, 0x10, 0);
printf("%p, %p, %p, %p\n", s, &(s->b), &((struct st*)0)->b, &((struct st*)2)->b);
}
}
/* 输出如下 */
0x221d010, 0x221d014, 0x4, 0x6&(s->b)表示取结构体s中b成员的地址。可以看到b在结构体指针s中的偏移量是0x221d014 - 0x221d010 == 4。&((struct st*)0)->b):将0强制转换为(struct st*)结构体类型的地址,起始地址为0。现在完整的看&((struct st*)0)->b)即为:以地址0为基址,取其成员b的地址。b在结构体中的偏移为4,所以取出来的地址即为4。
同理的
&((struct st*)2)->b),表示以地址2为起始地址,取其偏移4的地址,即为6。说明:在代码中使用
((struct st*)0)->b取的是地址0x4的值,运行时会发生错误,但是typeof(((struct st*)0)->b)表示取成员b的类型,可以进行运算(因为表达式本身永远不会被求值),不会发生错误。所以如下代码,表示定义一个和
member成员类型一样的变量__mptr,然后指向指针ptr指向的地方。这里也就是取得了程序中member成员的实际地址。1
const typeof(((type *)0)->member) * __mptr = (ptr);
offsetof()宏,定义如下:1
2
3
4
5/*
* Most 32 bit architectures use "unsigned int" size_t,
* and all 64 bit architectures use "unsigned long" size_t.
*/作用:取得
MEMBER成员到所在结构体起始地址的偏移长度。
最后,分析 container_of 宏 的最后一个语句:
1 | (type *)((char *)__mptr - offsetof(type, member)); |
结论:使用 member 成员的实际地址,减去该成员在该结构体的偏移量,即为该结构体的起始地址。
参考资料:
4.7 常见关键字
| 分类 | 分类 | 分类 | 分类 | 分类 |
|---|---|---|---|---|
| __user | asmlinkage |
一、__user
__user 关键字修饰的指针,指向的是用户空间的指针。
1 | // https://elixir.bootlin.com/linux/latest/source/tools/include/linux/types.h#L56 |
二、asmlinkage
asmlinkage:指定函数被调用时,不使用寄存器传递参数,参数全部通过堆栈进行传递。
定义在 /arch/x86/asm/linkage.h:
1 |
如 __attribute__((regparm(2))) 指定函数被调用时,仅使用 2 个寄存器传递参数,其余参数使用堆栈进行传递。
4.6 错误处理
4.7 消息日志
7 模块开发
Linux设备驱动程序第三版 p41 头文件说明:
1 |
primer、开发详解、设备开发、Linux Kernel Programming(签名、模块开发、语法)、kernel development、Linux 设备驱动 第三版
错误处理、