Linux 编程基础
😊
1 Linx 下 C 程序
1.1 C 标准
在 Linux 操作系统下进行 C 程序开发的标准主要有两个:C 标准和 POSIX 标准。
C89、C90。ANSI(美国国家标准委员会)C语言标准(x3.159-1989)最终于1989 年获批,随之于1990 年被 ISO(国际标准化组织)所采纳(ISO/EC 9899:1990)。通常将 C 语言的这一版本称为
C89或者(不太常见的)C90, Kernighan 和 Ritchie 所著的 The C Programming Language 第 2 版(1988)对其有完整描述。这份标准在定义 C 语言语法和语义的同时,还对标准 C 语言库操作进行了描述, 这包括 stdio 函数、字符串处理函数、数学函数、各种头文件等等。C99:1999 年,ISO 又正式批准了对 C 语言标准的修订版。通常将这一标准称为
C99,其中包括了对 C 语言及其标准库的一系列修改,诸如,增加了long long和布尔数据类型、C++风格的注释(//)、受限指针以及可变长数组等。自从 ANSI 委员会批准了 C99 修订版之后,确切说来,现在的 ANSI C 应该是 C99。C11(2011)、C18(2018)、C23(2023)。
C 语言标准独立于任何操作系统,换言之,C 语言并不依附于 UNIX 系统。这也意味着仅仅利用标准(语言库编写而成的 C 语言程序可以移植到支持 C 语言实现的任何计算机或操作系统上。
具体的支持情况要看编译器,而在使用上,我们写代码时主要关注的变化是:头文件、数据类型、编码格式等。
具体的变化可参考《C Primer Plus第6版-中文版》(网盘)、《C++ Primer Plus 第6版 中文版》、C语言标准——C89、C99、C11、C17、C2x。
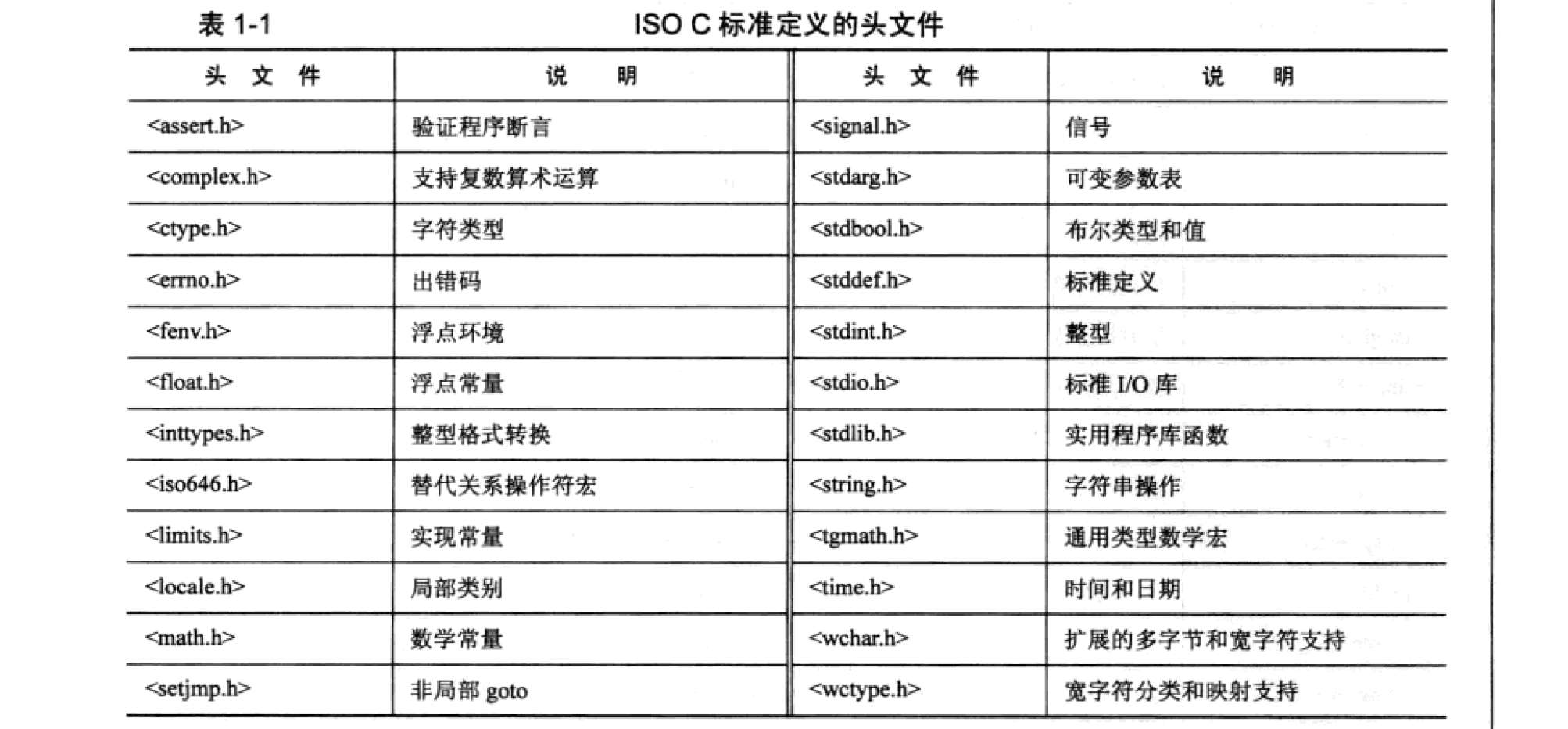
C89 不仅定义了 C 编程语言的语法和语义,而且还定义了一个标准库。ISO C 标准定义的头文件如表 1-1 所示。
![10.png]()
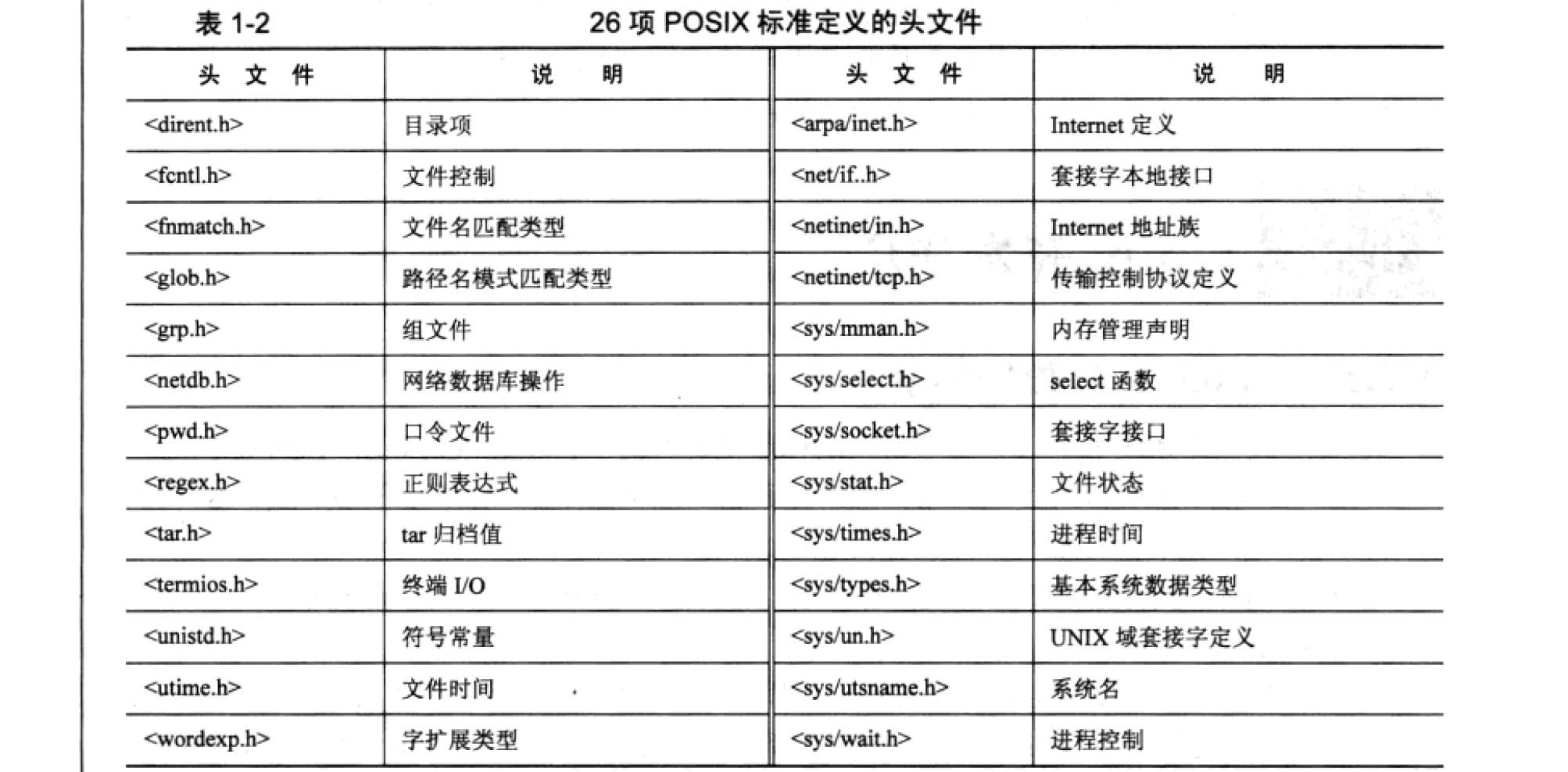
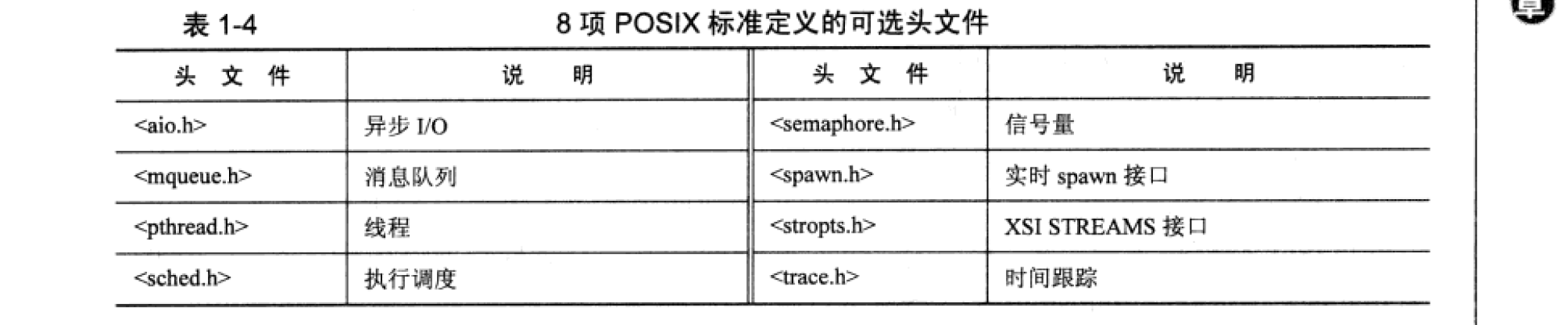
POSIX 标准,可移植操作系统 Portable Operating System Interface 的缩写,是 IEEE(电器及电子工程师协会)制定的标准。POSIX.1 和 POSIX.2 分别定义了兼容操作系统的 C 语言系统接口以及工具标准。Posix 是类 UNIX 系统都遵循的标准,例如 Ubuntu 下和 RedHat 下没有代码不需要移植可直接编译后执行,而在 Linux下基于 Posix 标准完成的代码就无法在 Windows下直接编译并执行。 表1-2 所示为26 项 POSIX 标准定义的头文件,表1-3 所示为 26 项 POSIX 标准定义的 XSI 扩展头文件,表1-4所示为:项 POSIX 标准定义的可选头文件。
![11.png]()
![12.png]()
![13.png]()
POSIX.1 版本1996 年诞生,对实时性和线程进行扩展。
POSIX.2,对 shell 和包括 C 编译器命令行接口在内的各种 UNIX 工具进行了标准化。
POSIX.1b 实时性扩展包括文件同步、异步 IO、进程调度、高精度时钟和定时器、采用信号量、共享内存,以及消息队列的进程间通信。这 3 种进程间通信方法的称谓前通常冠以
POSIX,以示其有别于与之类似而又较为古老的System V信号、共享内存以及消息队列。X/Open 公司和 The Open Group(XPG4、SUSv2)。
X/Open公司是由多家国际计算机厂商所组成的联盟,致力于采纳和改进现有标准,以制 定出一套全面而又一致的开放系统标准。该公司编纂的《X/Open 可移植性指南》是一套基于 POSIX 标准的可移植性指导丛书,如 XPG3、XPG4 两个版本。随后 XPG4 v2 版本被升级改造为 SUS(Single UNIX Specification)单一 UNIX 规范。并于 1997 年发布了 SUSv2 规范(也称作 XPG5)。
1996 年,X/Open 与开放软件基金会(OSF)合并,成立 The Open Group。
SUSv3 和 POSIX.1-2001。
由 IEEE、 Open 集团以及 IEC 联合技术委员会共同成立了奥斯丁公共标准修订工作组(CSRG)。该工作组正式批准了
POSIX 1003.1-2001,有时简称为POSIX.1-2001(后来也称作 SUSv3)。该标准取代了SUSv2、POSIX.1、POSIX.2以及大批的早期 POSIX 标准。SUSv3 规范了:- 基本定义(XBD)。包含了定义、术语、概念以及对头文件内容的规范。
- 系统接口(XSH)。主要包含对各种函数(在特定的 UNIX 实现中,这些函数要么是作为系统调用,要么是作为库函数来实现的)的定义。
- Shell 和实用工具(XCU)。明确定义了 shell 和各种 UNIX 命令的行为。
- 定义了对规范的两级符合度。其中之一是 XSI(X/Open 系统接口[X/Open System Interfacel])规范符合度,是 SUSv3 的超集。这些扩展支持以下特性:线程、mmap() 和 munmap()、 dlopen API、资源限制、伪终端、System V IPC、 syslog API、poll() 以及登录记账。后来称“符合 SUSv3 规范”是指“符合 XSI 规范”。
SUSV4 和 POSIX.1-2008。
2008 年,奥斯丁工作组完成了对己合并的 POSIX 和 SUS 规范的修订工作。发布了 SUSv4:
- SUSv4 为一系列函数添加了新规范。本书将会介绍以下新标准中定义的如下函数:dirfd0、fdopendir()、 fexecve())、 futimens()、 mkdtemp()、 psignal()、 strsignal() 以及 utimensat()。另一组与文件相关的函数,例如:openat()。
- SUSv4 废止了 SUSv3 中的某些函数,这包括 asctime()、 ctime()、 fiw()、 gettimeofday()、getitimer()、 setitimer() 以及 siginterrupt()。
- SUSv4 对 SUSv3 现有规范的各方面细节进行了修改。例如,对于应满足异步信号安全(async-signal-safe)的函数列表,二者内容就有所不同。

从 POSIX.1-2008 开始实现了大一统,如下图(实线表示标准间的直接过渡,虚线则表示标准间有一定的瓜葛,这无非有两种情况:其一,一个标准被并入了另一标准;其二,一个标准依附于另一个标准。):

目前新的标准有 POSIX.1-2017 及 POSIX.1-202x。
参考资料:
1.2 编码风格
一、GNU 编码规范
- 函数开头的左花括号放到最左边,避免把任何其他的左花括号、左括号或者左方括号放到最左边。
- 尽力避免让两个不同优先级的操作符出现在相同的对齐方式中。
- 每个程序开头都应该有一段简短的说明其功能的注释。
- 每个函数都加上注释,以说明函数做了些什么,需要哪些种类的参数,参数可能值的含义以及用途。
- 不要跨行声明多个变量。在每一行中都以一个新的声明开头。
- 当在一个
if语句中嵌套了另一个if-else语句时,应用花括号把if-else括起来。 - 要在同一个声明中同时说明结构标识和变量,或者结构标识和类型定义(typedef)。
- 尽量避免在
if的条件中进行赋值。 - 在名字中使用下划线以分隔单词,尽量使用小写;在宏或者枚举中通常使用大写常量。
- 使用一个命令行选项时,给出的变量应该在选项含义的说明之后,而不是选项字符之后。
二、Linux 内核编码規范
- 缩进采用
tab制表符。 - 在
if或者for循环中,将开始的大括号放在一行的最后,而将结束大括号放在本段语句结束行的第一位,函数中的大括号除外。 - 变量命名尽量使用简短的名字,简写或者单词间采用了
_隔开,比如sys_cfg_data。 - 函数最好短小精悍,一个函数最好只做一件事情,而且函数中的变量一般不超过
10个,大小一般都小于80行。 - 一个模块的注释一般注明了作者、版权、注释说明代码的功能,而不是说明其实现原理,这也和 Linux 的文化有关。
1.3 程序编译
Linux 应用程序表现为两种特殊类型的文件:可执行文件和脚本文件。
- 可执行文件:可以直接运行的 ELF 文件,类似于Windows 下的
.exe可执行文件。- 脚本文件:是一组指令的集合,这些指令将由另一个程序(即解释器)来执行。它们相当于 Windows 中的
.bat文件,.cmd文件或解释执行的BASIC程序。登录 Linux 系统后,交互的 shell 界面就是 bash 程序。Linux 并不要求可执行文件或脚本文件具有特殊的文件名或扩展名。文件系统属性用来指明一个文件是否为可执行的程序。
C 语言程序编译成一个可执行程序一般要经过以下 4 个步骤(GCC/G++ 是 GNU 中C 和 C++ 的编译器):
| 过程 | 解释 | GCC/G++ 参数 | 文件后缀 |
|---|---|---|---|
| 预处理(Preprocessing) | 对源代码文件中的文件包含 include、宏定义、预编译语句进行分析和替换。会将头文件所有代码在 #include 处展开。 |
-E |
C:.iC++: .ii |
| 编译(Compilation) | 将高级语言编译为汇编语言的文件。 | -s |
.s、.S |
| 汇编(Assembly) | 将汇编语言的文件汇编为二进制目标文件。 | -c |
.o |
| 链接(Linking) | 将静态库、目标文件等链接成可执行程序。 | -o |
NULL |
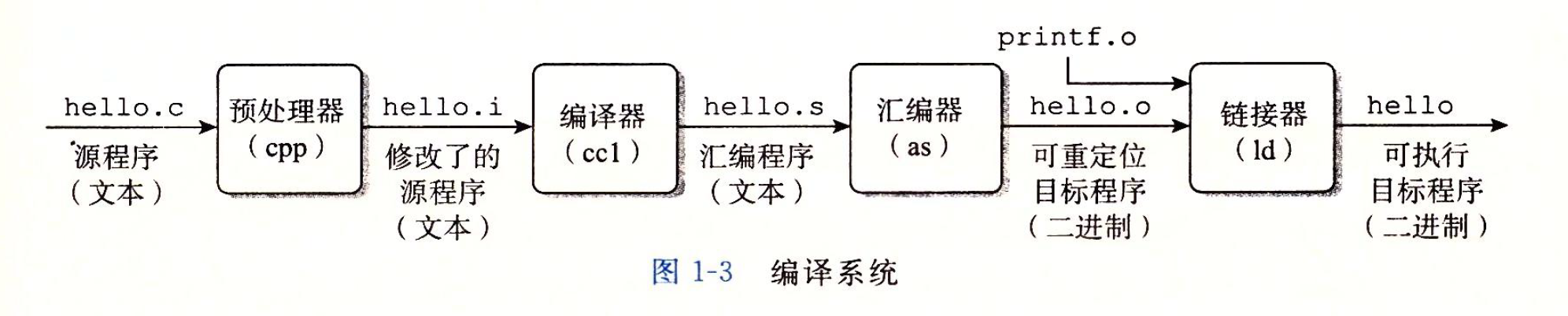
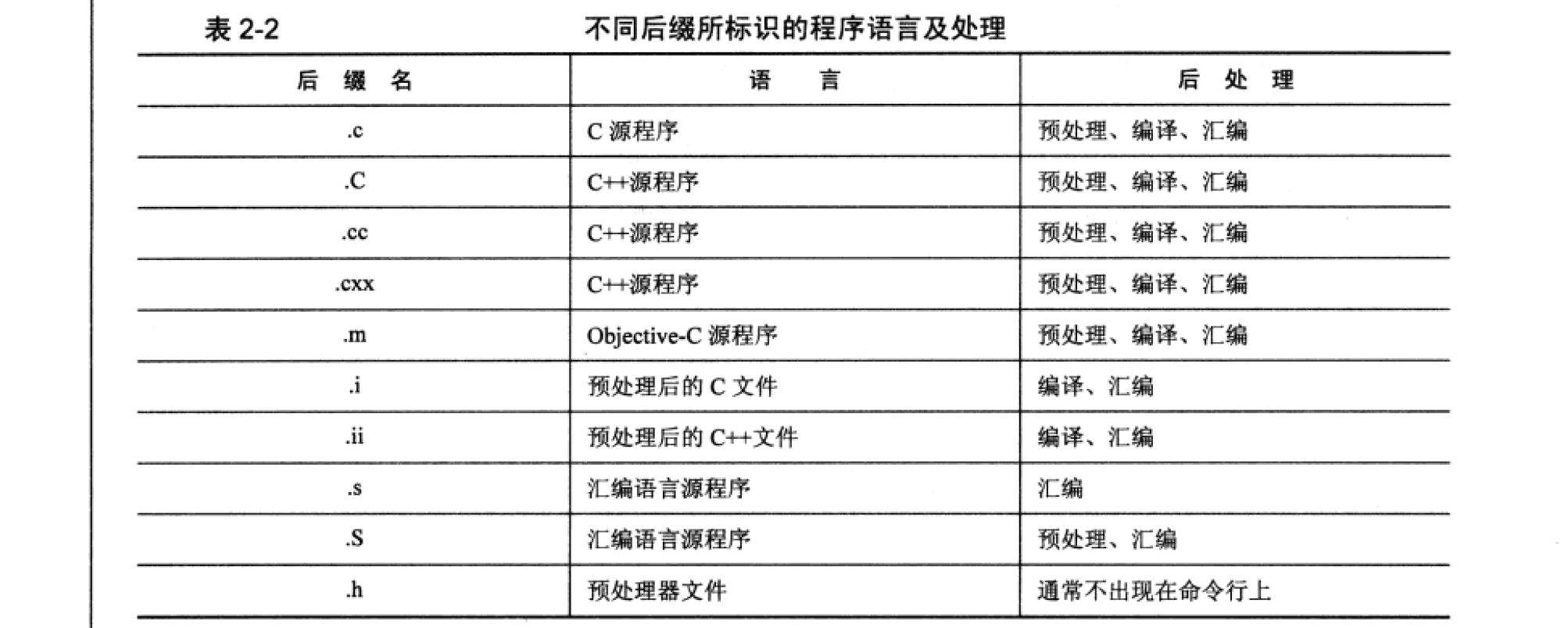
具体文件命名可以通过 GCC 帮助文件查看:
1 | [root@centos7 ~] |
使用一步编译链接生成可执行文件示例如下:
1 | [root@centos7 program] |
分步骤示例如下:
预处理。
1
2
3
4[root@centos7 program]
[root@centos7 program]
test.c test.i此时若是使用
cat查看test.i文件内容,会发现#include <stdio.h>被替换为该头文件的内容。编译(将高级语言转换为汇编语言)。
1
2
3
4
5
6
7
8[root@centos7 program]
[root@centos7 program]
test.c test.i test.s
[root@centos7 program]
00000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 |.ELF............|
00000010可以看到此时
test.s文件格式已经是目标文件了。汇编(将汇编语言转换为机器语言)。
1
2
3
4
5
6
7
8[root@centos7 program]
[root@centos7 program]
test.c test.i test.o test.s
[root@centos7 program]
00000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 |.ELF............|
00000010此时的
test.o也是目标文件。链接(生成可执行文件)。
1
2
3
4
5
6
7[root@centos7 program]
[root@centos7 program]
test.c test.exe test.i test.o test.s
[root@centos7 program]# ./test.exe
Hello World
参考:
- Linux 程序设计(第4版)
- Linux 高级程序设计中文第三版
- Linux环境编程:从应用到内核
2 库文件
库文件包括静态库和动态库(共享库,动态链接库),库文件也是目标文件 。标准的系统库文件一般存储在 /lib、/usr/lib 目录中。
库文件必须严格遵守命名规范:
- 必须以
lib开头。.a表示静态库,.so表示动态库。 libxxx.a,表示静态库文件。xxx为库文件名称,文件以.a结尾。libxxx.so.major.minor,表示动态库文件。xxx为库文件名称,major表示主版本号,minjor表示副(次)版本号。
在编译生成目标文件时,可以使用:
-L,指定库文件所在的绝对路径,参数-L和绝对路径之间没有空格。-l,指定库文件的名称,即上述的xxx,是lib和.a/.so中间的部分,参数-l和库名称之间没有空格。
示例:
1 | gcc -o test.exe -L/usr/lib64 test.c -lc_nonshared |
这条命令使用 /usr/lib64 目录下 c_nonshared 库文件来编译和链接生成 test.exe 程序。但是从这条命令上区分不出是静态库还是动态库。
2.1 静态库
静态库,也称作归档文件(archive),文件名以 .a 结尾。注意:静态库是由一个或多个目标文件归档生成的,使用 ar 命令。
组成静态库的文件是目标文件,所以需要使用 gcc -c 参数来生成目标文件。
说明:程序链接时需要将静态库一起链接到可执行文件中,这样的可执行程序可能会很大。
制作静态库示例:在 /home/program/staticlib 文件夹中有如下 4 个文件。
1 | [root@centos7 staticlib] |
将
addfunction、subfunction函数所在文件编译为目标文件。使用gcc -c参数,而不能直接链接为一个可执行程序,这是因为文件中没有main函数,会报错。1
2
3
4[root@centos7 staticlib]
[root@centos7 staticlib]
addfun.o subfun.o在不使用静态库的情况下链接生成可执行文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 生成 main.o 目标文件
[root@centos7 staticlib]
[root@centos7 staticlib]
addfun.o main.o subfun.o
// 将目标文件链接为可执行程序 main.exe
[root@centos7 staticlib]
[root@centos7 staticlib]
main.exe
[root@centos7 staticlib]# ./main.exe
a + b = 7
a - b = 8
addresult = 7, subresult = 8使用静态库链接生成可执行文件。
制作静态库(静态库是归档文件,使用
ar命令)。将addfun.o、subfun.o制作静态库。1
2
3
4
5
6
7
8
9
10
11[root@centos7 staticlib]
a - addfun.o
a - subfun.o
[root@centos7 staticlib]
libaddsub.a
// 查看静态库包含的文件,使用 -t 参数
[root@centos7 staticlib]
addfun.o
subfun.o在某些系统,尤其是从 Berkeley UNIX 衍生的系统中,要想成功地使用静态库,你还需要为静态库生成一个符号表,可以使用
ranlib xxx.a命令或者ar -s参数。在 Linux 中,当你使用的是 GNU 的软件开发工具时,这一步骤并不是必需的(但做了也无妨)。1
[root@centos7 staticlib]
编译
main.c并链接静态库,生成可执行程序。1
2
3
4
5
6
7
8
9[root@centos7 staticlib]
[root@centos7 staticlib]
main.exec
[root@centos7 staticlib]# ./main.exec
a + b = 7
a - b = 8
addresult = 7, subresult = 8这里用:
-L,指定库文件所在的绝对路径,参数-L和绝对路径之间没有空格。-l,指定库文件的名称,是lib和.a/.so中间的部分,参数-l和库名称之间没有空格。
2.2 动态库
静态库在程序链接时会全部链接进去,只要链接了该静态库的可执行程序运行时,每个进程中静态库的代码都会占用到大量的内存空间。所以应该尽量使用动态库,需要使用库的时候动态加载,物理内存中只保留一份动态库的内容,所有进程都可以映射这块物理内存到自己的进程空间中。
动态库命名格式:libxxx.so.major.minor ,xxx 为库文件名称,major 表示主版本号,minjor 表示副(次)版本号。动态库也是目标文件。
GCC 编译时使用参数:
-shared:表示要生成文件为动态链接库文件。-fPIC或fpic:开启动态链接库的基址重定位。
将源文件编译为动态库。
1
2
3
4[root@centos7 staticlib]
[root@centos7 staticlib]
libmathas.so链接生成可执行文件。
1
2
3
4[root@centos7 staticlib]
[root@centos7 staticlib]
main.exeas此时执行该可执行程序,运行失败:
1
2[root@centos7 staticlib]# ./main.exeas
./main.exeas: error while loading shared libraries: libmathas.so: cannot open shared object file: No such file or directory查看该程序的依赖库:
1
2
3
4
5[root@centos7 staticlib]
linux-vdso.so.1 => (0x00007ffca19f4000)
libmathas.so => not found
libc.so.6 => /lib64/libc.so.6 (0x00007eff7c6ff000)
/lib64/ld-linux-x86-64.so.2 (0x00007eff7cacd000)发现
libmathas.so并没有找到。可以知道可执行程序执行过程中,动态库的搜索方式和静态库是不同的,后面会总结。
配置动态库。
有常用三种方式可以进行配置:
- 1,在环境变量
LD_LIBRARY_PATH指定动态库搜索路径中添加动态库路径。 - 2,修改动态库搜索路径配置文件
/etc/ld.so.conf。 - 3,将动态库拷贝至动态库搜索路径
/lib, /usr/lib。
本例使用方法 2,关于环境变量的配置后面学了再弄。
查看
/etc/ld.so.conf文件:1
2[root@centos7 staticlib]
include ld.so.conf.d/*.conf可以看到,搜索路径在
ld.so.conf.d/*.conf配置文件中指定的路径。此时只需要在后面添加当前动态链接库的路径即可:修改文件之后,一定要使用ldconfig刷新ld链接器共享库的缓存列表/etc/ld.so.cache。1
2
3
4
5
6[root@centos7 staticlib]
/home/program/staticlib
[root@centos7 staticlib]
include ld.so.conf.d/*.conf
/home/program/staticlib执行程序:
1
2
3
4[root@centos7 staticlib]# ./main.exeas
a + b = 7
a - b = 8
addresult = 7, subresult = 8- 1,在环境变量
2.3 库文件搜索顺序
在可执行文件生成时,我们使用了 -L 参数来指定库文件所在的路径。而库名通过 -l 参数指定。如果有 libtest.a 和 libtest.so 两个库。我们链接时的命令如下:
1 | gcc main.c -L. -ltest -o main |
在有相同名称的动态库和静态库时,GCC/G++ 的链接程序,默认链接动态库,如果没有则会找静态库。如果指定只链接静态库,则需要使用参数 -static:
1 | gcc main.c -L. -ltest -static -o main |
(1)静态库链接时,搜索路径的顺序:
ld会去找gcc/g++命令中的参数-L指定的路径。- 再找
gcc的环境变量LIBRARY_PATH,它指定程序静态链接库文件搜索路径。 - 最后找默认库目录
/lib/usr/lib、/usr/local/lib。
(2)动态链接时,搜索路径顺序:
- 首先在环境变量
LD_LIBRARY_PATH所记录的路径中查找。 - 然后从缓存文件
/etc/ld.so.cache中查找。这个缓存文件由ldconfig命令读取配置文件/etc/ld.so.conf之后生成。 - 如果上述步骤都找不到,则到默认的系统路径中查找,先是
/usr/lib然后是/lib。
3 动态库版本及命名规则
本章节内容参考《程序员的自我修养–链接、装载与库 Chapter 8》。
3.1 共享库的兼容性
在介绍共享库的命名规则前,先说明下共享库的兼容性。
共享库的更新分为:
- 兼容性更新:原有接口保持不变
- 非兼容性更新:共享库更新了原来的接口,使用该共享库原有的接口可能不能正常运行或运行不正常。
这里所说的接口是二进制接口 ABI(Application binary interface),共享库的 ABI 跟程序语言有关很大的关心,导致 C 语言共享库 ABI 改变的4 种主要行为:
- 导出函数的行为发生改变,调用这个函数产生的结果和以前不一样。
- 导出函数被删除。
- 导出的数据结构发生变化,如成员顺序、类型改变,成员被删除等。不过,通常在结构末尾新增成员并不会导致不兼容。
- 导出函数接口发生变化,如参数类型、个数、顺序,返回值类型等。
C++ 开发的共享库,问题会更多,一般不建议使用 C++ 开发共享库,如果非要使用 C++ 开发共享库,需要注意一下事项,以防止 ABI 不兼容:
- 不要在接口类中使用虚函数,万不得已要使用虚函数时,不要随意删除、添加或在子类中添加新的实现函数,这种会导致类的虚函数表结构发生变化;
- 不要改变类中任何成员变量的位置和类型;
- 不要删除非内嵌的public或protected成员函数;
- 不要将非内嵌的成员函数改变成内嵌成员函数;
- 不要改变成员函数的访问权限;
- 不要在接口中使用模板;
- 最重要的是,不要改变接口的任何部分或干脆不要使用C++作为共享库接口。
3.2 共享库命名
有几种办法可用于解决共享库的兼容性问题,有效办法之一就是使用共享库版本的方法。Linux有一套规则来命名系统中的每一个共享库,它规定共享库的文件名规则必须如下:
$$libname.so.x.y.z$$
lib:前缀;.so:库的名字;x.y.z:版本号。x:主版本号(Major Version Number)y:次版本号(Minor Version Number)z:发布版本号(Release Version Number)
1、主版本号表示库的重大升级,不同主版本号的库之间是不兼容的,依赖于旧的主版本号的程序需要改动相应的部分,并且重新编译,才可以在新版的共享库中运行;或者系统必须保留旧版的共享库,使得那些依赖于旧版共享库的程序能够正常运行。
2、次版本号表示库的增量升级,即增加一些新的接口符号,且保持原来的符号不变。在主版本号相同的情况下,高的次版本号的库向后兼容低的次版本号的库。一个依赖于旧的次版本号共享库的程序,可以在新的次版本号共享库中运行,因为新版中保留了原来所有的接口,并且不改变它们的定义和含义。
3、发布版本号表示库的一些错误的修正、性能的改进等,并不添加任何新的接口,也不对接口进行更改。相同主版本号、次版本号的共享库,不同的发布版本号之间完全兼容,依赖于某个发布版本号的程序可以在任何一个其它发布版本号中正常运行,而无需做任何修改。当然现在Linux中也存在不少不遵循上述规定的“顽固分子”,比如最基本的C语言库 Glibc 就不使用这种规则,它的 C 语言共享库使用 libc-x.y.z.so 的命名方式。
共享库主版本号和次版本号决定了一个共享库的接口。
3.3 SO-NAME
- 定义:
- 每个共享库都有一个对应的 “SO-NAME”,这个 SO-NAME 即共享库的文件名去掉次版本号和发布版本号,保留主版本号,体现在
.dynamic节的DT_SONAME字段中。 - 系统会在共享库所在的目录中,建立一个和 SO-NAME 同名的软链接,该软链接指向该目录下最新版本的共享库。比如有
lib64/libfoo.so.2.6.1和lib64/libfoo.so.2.5.3,则 Linux 会在lib64目录下创建lib64/libfoo.so.2的软链接并指向lib64/libfoo.so.2.6.1文件。
- 每个共享库都有一个对应的 “SO-NAME”,这个 SO-NAME 即共享库的文件名去掉次版本号和发布版本号,保留主版本号,体现在
- 作用:简化共享库版本信息,方便版本升级后动态链接。
- 用途:用于
.dynamic节的DT_NEEDED、DT_SONAME两个字段。 - 原理:由于不同主版本号之问的共享库是完全不兼容的,较高的次版本号的共享库兼容较低的次版本号的共享库。
- 说明:SO-NAME 并不等同于
DT_SONAME,他是共享库版本的简化,应用在DT_SONAME、DT_NEEDED等字段中。
举例说明:A 文件依赖于 B 文件,如果 A 文件的 DT_NEEDED 记录值是 libfoo.so.2.6.1,当该文件版本升级至 libfoo.so.2.7.2 后,为了节约空间原目录下已经不存在旧版本共享库,且“由于不同主版本号之问的共享库是完全不兼容的,较高的次版本号的共享库兼容较低的次版本号的共享库”,导致 A 文件无法链接到 B 文件。解决方法:如果将共享库的 SO-NAME 名 libfoo.so.2 写到共享库的 DT_NEEDED,因为每次更新共享库时系统都会更新 SO-NAME 软链接指向的最新版本共享库。
1 | [root@centos-7 program] |
4 目标文件常用命令
4.1 ar 归档静态库
静态库,也称作归档文件(archive),由一个或多个目标文件归档而成,按惯例它们的文件名都以 .a 结尾,使用 ar 命令来进行归档。
ar 命令用于建立或修改档案文件,或是从档案文件中抽取文件。
语法(常用的参数是 crv):
1 | ar [-dmpqrtx][cfosSuvV][a<成员文件>][b<成员文件>][i<成员文件>][备存文件][成员文件] |

1 | [root@centos7 staticlib] |
4.2 ldd 查看动态依赖库
ldd 显示可执行程序、动态库的依赖情况。
选项 (OPTIONS)
- -v 显示 ldd 的版本号.
- -V 显示动态连接器 ld.so 的版本号.
- -d 进行重定位(relocation), 而且报告缺少的函数(仅限于 ELF).
- -r 对数据目标 (data object) 和函数进行重定位, 而且报告缺少的数据目标 (仅限于 ELF).
1 | // 查看动态库依赖情况 |
4.3 nm 查看目标文件中函数
nm 是 name 的缩写,用来分析二进制文件、库文件、可执行文件中的符号表。
参数不常用,此处不在罗列,但是输出符号中关于函数的需要特别说明:
1 | [root@centos7 staticlib] |
T:该符号在代码段,也表示在当前文件中定义的函数。U:在当前文件中调用的函数,但不是在当前文件中定义的函数。
| 符号类型 | 说明 |
|---|---|
| A | 该符号的值是绝对的,在以后的链接过程中,不允许进行改变。这样的符号值,常常出现在中断向量表中,例如用符号来表示各个中断向量函数在中断向量表中的位置。 |
| B | 该符号的值出现在非初始化数据段(bss)中。例如,在一个文件中定义全局static int test。则该符号test的类型为b,位于bss section中。其值表示该符号在bss段中的偏移。一般而言,bss段分配于RAM中。 |
| C | 该符号为common。common symbol是未初始话数据段。该符号没有包含于一个普通section中。只有在链接过程中才进行分配。符号的值表示该符号需要的字节数。例如在一个c文件中,定义int test,并且该符号在别的地方会被引用,则该符号类型即为C。否则其类型为B。 |
| D | 该符号位于初始话数据段中。一般来说,分配到data section中。例如定义全局int baud_table[5] = {9600, 19200, 38400, 57600, 115200},则会分配于初始化数据段中。 |
| G | 该符号也位于初始化数据段中。主要用于small object提高访问small data object的一种方式。 |
| I | 该符号是对另一个符号的间接引用。 |
| N | 该符号是一个debugging符号。 |
| R | 该符号位于只读数据区。例如定义全局const int test[] = {123, 123};则test就是一个只读数据区的符号。注意在cygwin下如果使用gcc直接编译成MZ格式时,源文件中的test对应_test,并且其符号类型为D,即初始化数据段中。但是如果使用m6812-elf-gcc这样的交叉编译工具,源文件中的test对应目标文件的test,即没有添加下划线,并且其符号类型为R。一般而言,位于rodata section。值得注意的是,如果在一个函数中定义const char *test = “abc”, const char test_int = 3。使用nm都不会得到符号信息,但是字符串“abc”分配于只读存储器中,test在rodata section中,大小为4。 |
| S | 符号位于非初始化数据区,用于small object。 |
| T | 该符号位于代码区text section。 |
| U | 该符号在当前文件中是未定义的,即该符号的定义在别的文件中。例如,当前文件调用另一个文件中定义的函数,在这个被调用的函数在当前就是未定义的;但是在定义它的文件中类型是T。但是对于全局变量来说,在定义它的文件中,其符号类型为C,在使用它的文件中,其类型为U。 |
| V | 该符号是一个weak object。 |
| W | 该符号是没有被明确标记为weak object的弱符号类型。 |
| - | 该符号是a.out格式文件中的stabs symbol。 |
| ? | 该符号类型没有定义。 |
4.4 gcc 常用命令
| 选项 | 解释 |
|---|---|
| -ansi | 只支持 ANSI 标准的 C 语法。这一选项将禁止 GNU C 的某些特色, 例如 asm 或 typeof 关键词。 |
| -c | 只编译并生成目标文件。 |
| -DMACRO | 以字符串”1”定义 MACRO 宏。 |
| -DMACRO=DEFN | 以字符串”DEFN”定义 MACRO 宏。 |
| -E | 只运行 C 预编译器。 |
| -g | 生成调试信息。GNU 调试器可利用该信息。 |
| -IDIRECTORY | 指定额外的头文件搜索路径DIRECTORY。 |
| -LDIRECTORY | 指定额外的函数库搜索路径DIRECTORY。 |
| -lLIBRARY | 连接时搜索指定的函数库LIBRARY。 |
| -m486 | 针对 486 进行代码优化。 |
| -o FILE | 生成指定的输出文件。用在生成可执行文件时。 |
| -O0 | 不进行优化处理。 |
| -O 或 -O1 | 优化生成代码。 |
| -O2 | 进一步优化。 |
| -O3 | 比 -O2 更进一步优化,包括 inline 函数。 |
| -shared | 生成共享目标文件。通常用在建立共享库时。 |
| -static | 禁止使用共享连接。 |
| -UMACRO | 取消对 MACRO 宏的定义。 |
| -w | 不生成任何警告信息。 |
| -Wall | 生成所有警告信息。 |
5 main 函数
5.1 输入参数
本章节并不是讲解函数执行流程,执行流程在 Windows 内核部分(x86 异常顶层处理)已经分析过了。本章节主要讲解输入参数的处理。
main 函数原型如下:
1 | int main(int argc, char* argv[], char* envp[]) |
main 函数是带参数的,我们在 Linux 上使用的命令,如 ls -al 都是带参数的,这些参数都是输入给 main 函数的。3 个参数的意义如下:
argc:以空格作为分隔,命令行输入的字段个数。由系统根据输入的字段数量自动进行统计,不是用户手动指定。argv:是一个字符串指针数组,从argv[0]开始存储输入的每个字段,空格不存储。因为 C 语言没有 String 类,所以使用二级指针存储字符串。envp:环境变量参数。保存当前进程所属用户所有的系统环境变量。

举例说明:
1 | ./test.exe -b time -k year |
举例:
1 | [alvin@centos-7 program]$ cat test_main_arg.c |
输出:
1 | [alvin@centos-7 program]$ ./test_main_arg.exe -b time -k year |
5.2 getopt 函数
Linux 的标准 C 库(ANSI C)提供了两个专门支持处理命令函输入的参数,getopt、getopt_long。借用这两个函数,可以方便开发者更好地处理从 main 输入的命令行。这两个函数包含在 /usr/include/unistd.h 头文件中。
1 | int getopt(int argc, char * const argv[], const char *optstring); |
关于 getopt 函数说明:
| 分类 | 说明 |
|---|---|
| 参数 | 1、 argc、argv 即从 main 函数前 2 个参数传递而来。2、 optstring:该程序可用的参数选项,以 -x 开头的表示参数选项。 有着独特的格式,如 ab:m::k:,意义如下:- 单个字符:表示选项,后面不需要接参数。 - 字符后接一个冒号 b::表示 -b 选项之后必须跟一个参数。- 字符后接两个冒号 m:::表示 -m 选项之后接一个可选参数。如果有参数,选项和参数之间不能有空格。 |
| 系统变量 | getopt 函数还会定义 4 个系统变量,生命周期为父函数的生命周期(调用 getopt 的函数),并不是调用一次 getopt 这几个变量就被刷新。如果 getopt 函数成功执行,则会返回匹配到的相关参数选项,如上如果匹配到选项 a 则会返回字母 a 的 ASCII,同时设置如下变量。optarg:指向匹配到的参数字符串,如果没有参数则为 NULL。optind:下次调用 getopt 函数时,要处理的 argv 数组元素的下标。opterr:正常运行状态下为 0。非零时表示存在无效选项或者缺少选项参数,并输出其错误信息。optopt:当命令行中的选项不包括在 optstring,则该选项将存储在 optopt 中,getopt 函数返回 ?。 |
| 返回值 | 每次调用 getopt 函数返回值都不一样。1、正常情况下返回匹配到的参数选项字符 ASCII,相应的参数值字符串由 optarg 指向。2、如果参数解析完毕或参数无效( optiond 指向的参数无意义),则返回 -1。3、命令行中的参数在 optstring 中没有找到,返回 ?。 |
该函数一般用在一个循环里面,当返回值 != -1 时就在循环里面进行处理。
举例:
1 | [alvin@centos-7 program]$ cat test_getopt.c |
输出:
1 | [alvin@centos-7 program]$ ./test_getopt.exe -u -c time -pproc -k |
6 错误处理
6.1 errno
函数调用过程中,如存在权限不足、参数错误等错误时,函数都会返回一个值,返回值常常是一个正/负整数(类似于Windows 下的 NTSTATUS 类型返回值),可根据返回值知道错误原因。
在 Linux 下,函数返回的错误号称为 errno,其对应的常量值定义在 /usr/include/asm-generic/errno.h 中,这些常量大部分以 E 字母开头。关于 errno 号的定义如下:
1 |
|
可以看到,宏 errno 即为错误号,为整数,替换上一行的 int。对于 errno 应当知道两条规则。
- 第一条规则是:如果没有出错,则其值不会被一个例程清除。因此,仅当函数的返回值指明出错时,才检验其值
- 第二条是:任一函数都不会将
errno值设置为0,在<errno.h>中定义的所有常量都不为0。
errno 号常量举例如下:
1 | /* /usr/include/asm-generic/errno.h */ |
C 标准定义了两个函数:strerror、perror,它们帮助打印出错信息。
6.2 strerror_r
strerror 函数定义在 /usr/include/string.h 中,将对应的 errno 号映射为对应的错误描述字符串,并且返回指向此字符串的指针。
1 | /* /usr/include/string.h */ |
__errnum 为 errno 号。
举例:
1 |
|
输出为:
1 | [*] Error: No such file or directory |
注意:由于 strerror 函数返回的是一个字符串的地址,可能会被更改,所以 strerror 函数不是线程安全的,可以使用 strerror_r 线程安全函数替代:
1 |
|
__buf:用来接收__errnum所映射的字符串。__buflen:参数二__buf的长度。
所以上面的代码可以改为:
1 |
|
返回值:成功时返回 1,失败时返回 -1。有意思的是,这个函数在错误时也设置 errno。
6.3 perror
Linux 下错误信息的处理要比 Windows 下更便捷,在 Linux 下,当一个函数出错时,可以调用 perror 函数。
perror 函数作用:该函数向 stderr(标准错误输出)打印以 str 指向的字符串为前缀,紧跟着一个冒号, 然后输出由 errno 表示的当前错误的字符串。
1 |
|
举例:
1 |
|
输出:
1 | [*] : No such file or directory |
参考资料:
- 《Unix 环境高级编程 第二版 1.7》
- 《Linux 系统编程 第二版 1.4.8》