CPU 推测执行漏洞及缓解 via KVA Shadow
😄
写完本章内容后,才发现《Windows Internals 7 Part2》有很好的讲解这个 CPU 推测执行的漏洞细节。
0 CPU 推测执行漏洞
虽然 Meltdown(熔毁,CVE-2017-5754)、Spectre(幽灵,CVE-2017-5753&CVE-2017-5715)漏洞在发现时间上存在前后关系,但是在后来的研究以及漏洞缓解实施过程中,都将这些漏洞统称为 CPU 推测执行的变体(CPU Speculative execution Variant)。
参考:
- 《Mitigating Risk of Spectre and Meltdown Vulnerabilities》
- 《007: Low-overhead Defense against Spectre Attacks via Program Analysis》
| 变体(Variant) | CVE | 原理 | 缓解措施 |
|---|---|---|---|
| 1 | CVE-2017-5753(Spectre) | 在有分支判断的地方,代码编译为 JCC 条件跳转指令。攻击者可以通过循环训练 CPU 对跳转的训练,最后利用 CPU 来推测执行 JCC 的目的地。 |
软件缓解:Microsoft Visual C/C++ 编译器提供了一个编译选项 Qspectre,通过在潜在易受攻击的代码位置插入 lfence 序列化指令来启用缓解。 |
| 2 | CVE-2017-5715(Spectre) | 在有间接跳转或调用,如 jmp rax/jmp [rax]/call rax/call [rax]/ret 等间接分支时,CPU 利用 BTB、RSB 中的信息进行预测并跳转。攻击者可以污染 BTB、RSB 来修改跳转目的地,从而实施攻击。 |
软件缓解: 1、使用 Retpoline 将易受攻击的间接分支替换为非易受攻击的指令序列,强制 CPU 跳转到真实目的地而不是 BTB/RSB 建议的预测目标。 2、使用 lfence 指令(可选择)。3、RSB 填充 + BTB 刷新。 硬件缓解: 1、IBPB:同一权限级别下,之前的跳转地址不会影响之后的跳转预测。 2、IBRS:内核权限代码不得使用分支预测器中的用户代码,用户权限代码也不得使用分支预测器中的内核代码。 |
| 3 | CVE-2017-5754(Meltdown) | 在指令中,如果前后指令不存在依赖关系,如果前面一条指令需要访问内存或导致异常时,CPU 有可能已经执行了乱序执行了后面的指令。攻击者可以利用瞬态指令来泄露内核数据。 | 软件缓解:KVA Shadow、lfence 指令(乱序之行)。 |
1 Meltdown 和 Spectre
Meltdown 和 Spectre 是两个 CPU 漏洞,对应的 CVE 编号是 Meltdown(熔毁,CVE-2017-5754)、Spectre(幽灵,CVE-2017-5753&CVE-2017-5715)。目前已经衍生出多种变种利用方式。
这两个 CPU 缺陷几乎影响了自 Pentium Pro(1995)以来开发的所有现代处理器。这些缺陷源于两个关键的CPU功能:乱序执行和推测执行。
- Spectre:基于分支预测的推测执行(Speculative execution from branch prediction)。
- Meltdown:基于乱序执行(Out-of-order execution)的推测执行。

两个漏洞非常相似,都是组合 CPU 设计缺陷、侧信道攻击、内存访问越界来实施攻击,以破坏地址空间隔离,泄露内核数据。
这两个漏洞的研究报告:《Meltdown and Spectre》。
Spectre 影响的 CPU 范围较 Meltdown 广,用于缓解 Meltdown 的 KAISER 机制不能防止 Spectre。
CVE-2017-5753、CVE-2017-5715、CVE-2017-5754 都是 Spectre 的变体:
- 变体1,有条件的分支误判:CVE-2017-5753(Spectre)。
- 变体2,间接分支误判:CVE-2017-5715(Spectre)。
- 变体3,乱序执行:CVE-2017-5753(Meltdown)。
2 漏洞原理
2.1 Spectre(幽灵)
漏洞原理
几十年前,为了加快处理器的执行速度以提高性能,其中一项技术就是推测执行(Speculative Execution):在遇到分支判断时,让处理器猜测可能执行的方向,并在这个路径上提前执行指令。
举个示例,在分支判断的地方访问了未缓存的内存,由于访问内存要比 CPU 执行慢得多,通常需要数百个时钟周期才能取到内存中的值,CPU 不会空闲下来而浪费这些周期时间,而是尝试去猜测该控制流的方向。CPU 先将当前点(Checkpoint)的寄存器状态保存起来,然后在猜测的路径上继续往下执行。当从内存传送过来的值到达处理器后,CPU 会检查初始猜测的正确性。如果猜测错误,CPU 会通过将寄存器状态恢复为存储的检查点来丢弃不正确的推测执行(称为回滚),这种情况下与空闲是相当的性能;如果猜测正确则继续往下执行,从而产生性能的提升。
而幽灵漏洞就是利用不正确的猜测执行,幽灵攻击诱使 CPU 推测执行正确控制流不应该执行的指令。漏洞发现者将这部分正确控制流不会执行,而 CPU 能推测执行的指令称为 Transient instructions(瞬态指令)。利用 Transient instructions 从受害者的内存地址空间中泄露内核信息。
不幸的是,尽管架构状态被回滚了,仍然有些副作用,比如 TLB 或缓存状态并没有被回滚。这些副作用随后可以被黑客通过侧信道攻击(Side Channel Attack)的方式获取到缓存的内容。如果攻击者能触发推测执行去访问指定的敏感数据区域的话,就可能可以读取到原本是其它用户或更高特权级的敏感数据。
基于这样的推测执行能够衍生出多种不同的变体利用方式,如利用条件分支的推测执行(CVE-2017-5753)、利用间接分支的推测执行(CVE-2017-5715)。
漏洞还原
本文以其中一种变体——利用条件分支的推测执行来泄露内核数据。
主要参考Meltdown Reloaded: Breaking Windows KASLR by Leaking KVA Shadow Mappings、Spectre Attacks: Exploiting Speculative Execution、Spectre and Meltdown explained: A comprehensive guide for professionals。
一、触发漏洞
如下代码:
1 | unsigned __int64 array_size = 1 |
参数 pos 完全由攻击者控制,如果此时 pos >255,CPU 没有等待条件判断,同时还会猜测数组边界检查为真(实际上 CPU 直接访问了越界数组指向的内存),假设此时 array2[pos] = 0x41,则接下来 CPU 会访问 array1[0x41],并将访问到的数据缓存 Cache。当最终确定条件分支及数组越界检查的结果后,CPU 会发现其错误并进行回滚。但是访问 array1[0x41] 的数据已缓存 Cache,CPU 没有刷新该缓存,攻击者就可以分析该缓存的内容,从而得到越界访问的数据。
注意:0 <= array2[pos] <= 255,所以数组 array1[X] 不会越界,方便后面分析缓存的值(无符号字符为1字节8位,2^8=256)。除此之外,还要要求 array1 数组之前没有被访问过也就没有相关缓存信息。
所以可以构造如下代码:
1 | array1[ array2[0xffff8000`12345678 - &array2] ]; |
这样就可以将 CPU 推测执行 array2[0xffff8000'12345678] 的地址缓存起来,然后分析缓存,从而得到地址 0xffff8000'12345678 泄露的值。
关于缓存:
现代 CPU 一般都会在内部设置缓存结构,然后将高速缓存划分为固定大小的块(或叫做行Lines),典型的每行 64/128 字节,内存是按行的粒度进行缓存的。档处理器需要内存中的数据时,首先就要去高速缓存中进行检索,检索不到才会去访问物理内存。
Intel 处理器通常具有三级缓存,每个核心都有自己的 L1、L2 缓存,还有一个所有核心共享的 L3 缓存(也称为LLC)。
处理器必须使用缓存一致性协议确保每个内核的 L1和L2缓存是一致的,通常基于 MESI 协议。特别是,使用 MESI 协议或其某些变体意味着对一个内核的内存写入操作将导致其他内核的 L1 和 L2缓存中的相同数据副本被标记为无效,这意味着将来访问其他内核上的这些数据将无法从L1或 L2 缓存中快速加载数据。
二、分析缓存:
由于 CPU 使用缓存来存储最近访问的内存的内容,并且缓存比常规内存快得多,因此我们有机会通过观察不同缓存行的访问时间来推断访问了哪些元素。
推断访问了哪个缓存行的典型方法是(Flush+Reload技术):
首先刷新所有缓存行,即刷新数组每个元素的 CPU 缓存。
1
2
3
4
5for ( i = 0 ; i < 256 ; i ++ )
{
// Invalidating cache
_mm_clflush ( &array1 [ i ] );
}然后触发受害者内存访问,将访问的数据进行缓存。
1
2
3
4
5
6
7Leaker_function ( unsigned __int64 pos )
{
if ( pos < array_size )
{
temp_value = array1[ array2[0xffff8000`12345678 - &array2] ];
}
}假设
array2[0xffff8000'12345678 - &array2] = 0x41,则在下面使用__rdtscp检索数组array1每个元素访问时间时,应该是array1[0x41]使用的时间最少。为访问每个缓存行计时(依次计时访问数组
arry1每个元素),受害者访问的元素将产生最低的时间。
三、训练
为诱导分支预测推测执行,在错误的推测执行前应该尽可能的训练 CPU 推测正确的分支判断,使得 CPU 在类似的分支判断前按照之前的经验进行推测执行。
完整利用代码(参考Meltdown Reloaded: Breaking Windows KASLR by Leaking KVA Shadow Mappings):
1 | // Kernel address to be read |
Github 利用项目Meltdown KVA Shadow Leak。
总结
幽灵(Spectre)漏洞利用 CPU 的分支预测+推测执行。推测执行时不会对内存访问权限检查,以及数组越界等检查。似乎 CPU 推测执行时都会推测执行条件”满足“而继续往下推测执行,等最后判断条件不满足时再回滚寄存器内容或已访问内存的内容。但是此时已访问的内存内容已经缓存至高速缓存了,后面就可以利用侧信道攻击(根据访问内存时间从而判断缓存信息)。
2.2 Meltdown(熔断)
熔断也是利用 CPU 的推测执行,只不过不像幽灵漏洞那样是在分支预测时进行推断执行,而是在乱序执行中进行的推测执行。
在用户空间执行的代码可以利用熔断漏洞来泄露内核空间的数据。
如下代码:
1 | int a = 1; |
由于 b 的值依赖于 a 的值,所以 CPU 在执行时可能会进行乱序执行如下:
1 | int a = 1; |
下面推测执行的指令不依赖于前面的指令。
论文指出可乱序执行的指令:当遇到分支条件时,位于该路径上且没有任何依赖关系的指令可以提前执行,如果预测正确,则立即使用它们的结果。如果预测不正确,重新初始化统一保留站来回滚到正常状态(Instructions that lie on that path and do not have any dependencies can be executed in advance and their results immediately used if the prediction was correct. If the prediction was incorrect, the reorder buffer allows to rollback to a sane state by clearing the reorder buffer and re-initializing the unified reservation station.)。
可以构造以下代码:
1 | unsigned char array1[256] = { 0 }; |
在用户空间的程序访问 __try 中的内核地址导致异常,在进行异常处理前,由于乱序执行,CPU 可能已经执行了下面的访问数组的指令(瞬态指令,Transient instructions)。因为访问数组指令不依赖于前面的指令,然后访问到的 array1 数据已经缓存至告诉缓存。
在正常程序流程中,瞬态指令部分不应该被执行到。
然后和上面的幽灵漏洞一样,使用侧信道攻击,借助 Flush+Reload 技术来分析缓存。假设地址 0xffff8000'12345678 中的数据为 84,则高速缓存中缓存的应该是 array1[84]。Flush+Reload 技术分析访问数组 array1 每个元素访问时间如下:
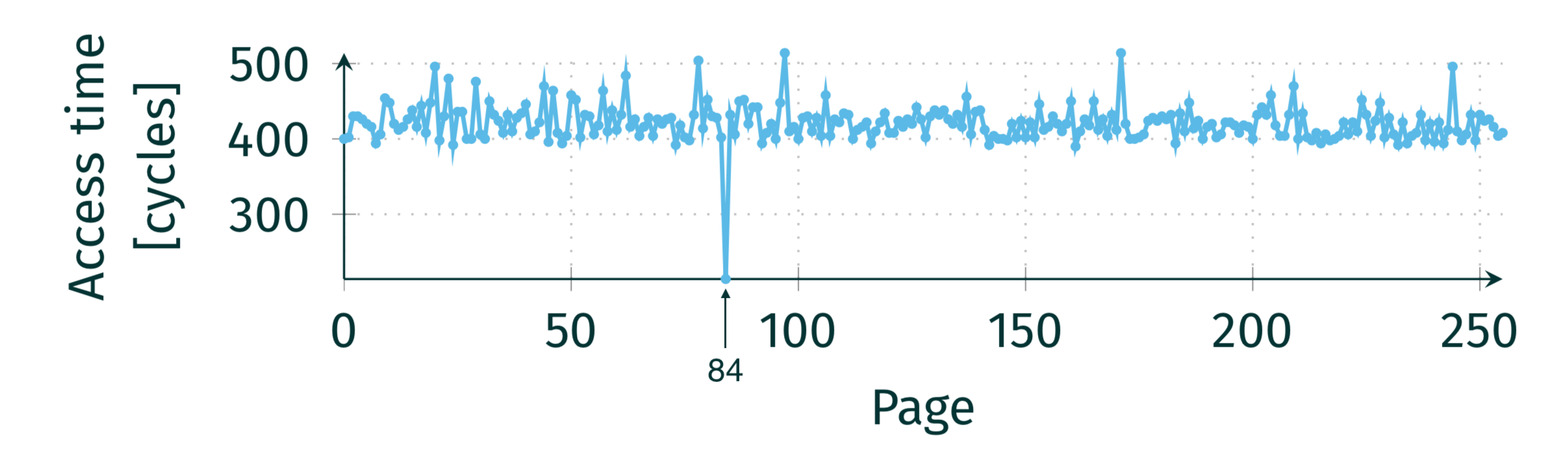
2.3 缓解措施
可参考:《幽灵・熔毁・预兆》。
- 硬件:重新设计 CPU 以确保在发射读取指令之前进行权限检查,英特尔已于 Coffee Lake Refresh 及后续微架构中修补漏洞,但之前的 CPU 就只能软件修补了;
- 软件:各大操作系统都推出了内核页表隔离补丁来抵御漏洞:
- Linux 4.15 已部署 Kernel Page-Table Isolation(内核页表隔离,KPTI);
- Windows 10 build 17035 已部署 KVA Shadow;
- macOS 10.13.2 / iOS 11.2 已部署 Double Map;
- ……
https://www.4hou.com/posts/jL6y
https://www.anquanke.com/post/id/93599
https://blog.yzsun.me/spectre-meltdown-foreshadow/
http://www.qfrost.com/WindowsKernel/KVAS/
https://zhuanlan.zhihu.com/p/33427373
https://zerosum0x0.blogspot.com/2019/11/fixing-remote-windows-kernel-payloads-meltdown.html
https://blog.csdn.net/xuandao_ahfengren/article/details/112135179
https://key08.com/usr/uploads/2022/05/910489819.pdf
3 Meltdown 缓解措施
微软在 2018.1.3 发布更新 以缓解如下的漏洞,并给出了相关的说明Mitigating speculative execution side channel hardware vulnerabilities。其中提到 Hypervisor address space segregation、Split user and kernel page tables 等诸多措施。
- Variant 1: bounds check bypass (CVE-2017-5753), (Spectre)
- Variant 2: branch target injection (CVE-2017-5715), (INTEL-SA-00088), (Spectre)
- Variant 3: rogue data cache load (CVE-2017-5754), (Meltdown)
其中关于 Split user and kernel page tables:
这种缓解措施被称为 Windows 上的内核虚拟地址(KVA)阴影(Windows 下的内核页表隔离),它通过每个进程创建两个页面目录基来缓解被称为 Meltdown(CVE-2017-5754)的推测技术。第一个映射“用户”页面表,该表仅包含用户模式映射和少量内核过渡页面。第二个映射了“内核”页面表,其中包含该过程的用户和内核映射。也就是每个进程提供两个 CR3,一个用于用户空间,一个用于内核空间。专门用来缓解 Meltdown 漏洞。关于 KVA Shadow 的缓解措施,微软也给了说明文档KVA Shadow: Mitigating Meltdown on Windows。
本章节主要先研究 KVA Shadow 缓解措施,然后研究在 Windows 内核中的一些具体的缓解 Spectre 代码示例。
KVA Shadow 用来缓解 Meltdown,并不能缓解 Spectre。
3.1 KVA Shadow
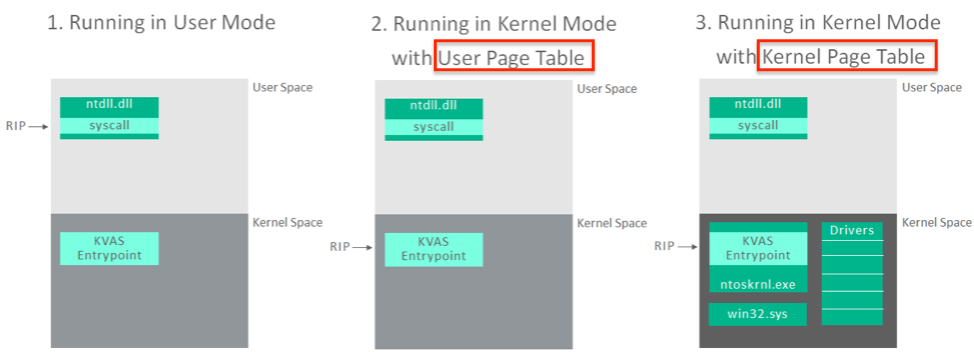
利用 Meltdown 漏洞可以在用户空间泄露内核空间的数据,这是因为每一个进程共享系统内核空间,且用户空间可以通过系统调用或中断处理等方式进入内核。这些实现的基础就是线性地址的连续性映射,如在一个进程中,用户空间地址范围 0~0x00007FFF'FFFFFFFF,内核空间地址范围 0xFFFF800'00000000~0xFFFFFFFF'FFFFFFFF。
KVA Shadow 的核心原理就是:使用 2 个 CR3 来构建两套页表,一个 CR3 来映射用户空间使用的线性地址,另一个 CR3 来映射内核空间使用的线性地址。前者叫做 Shadow CR3 或 Shadow PLM4 或 User CR3,后者叫做 Kernel CR3,以实现页表隔离。
- Kernel CR3:映射用户空间及内核空间地址,仅在内核模式下使用。
- User CR3:仅映射用户空间地址及一小部分内核空间地址。
这一小部分内核空间地址实际上存放的是 GDT、IDT,及一些用来提供处理系统调用、中断处理函数的资源,在 ntoskrnl.exe 这部分代码存放在 .KVASCODE 段中,而非 .text 段。
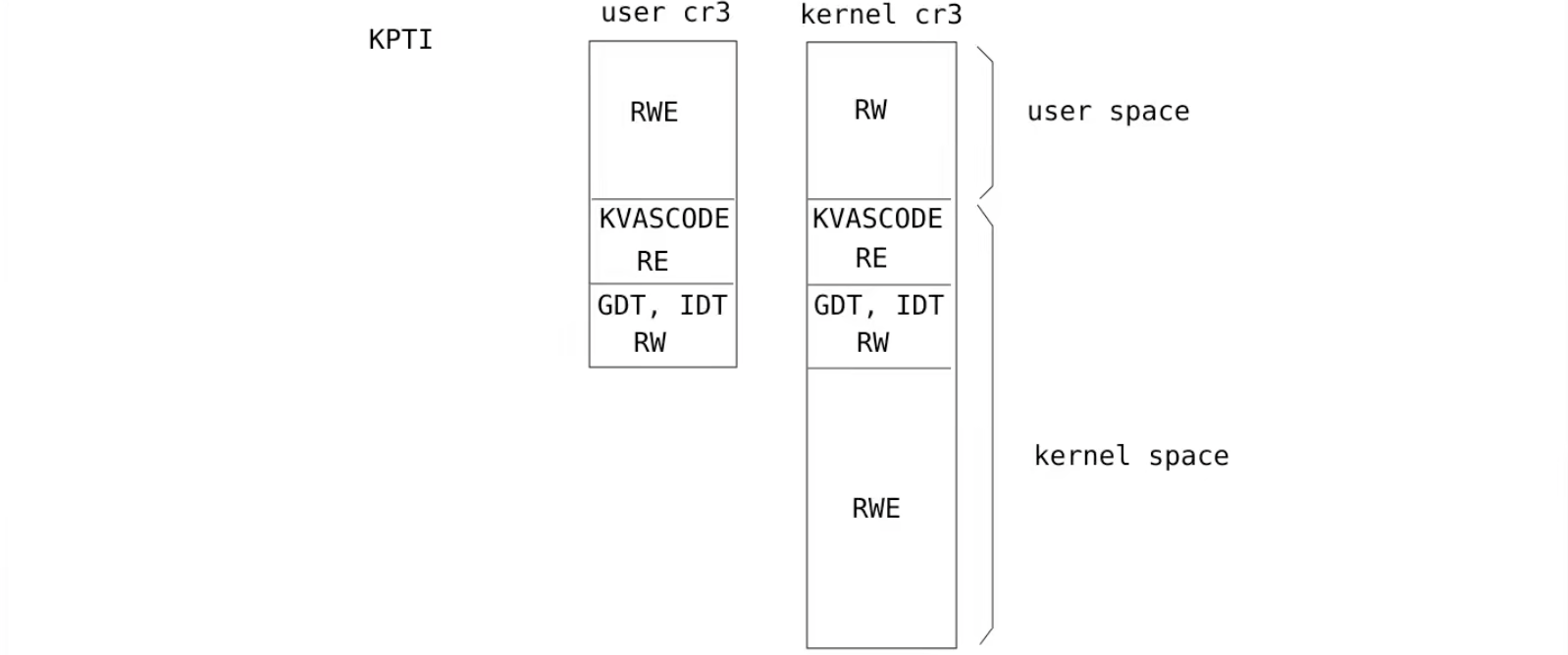
当选择启用 KVA Shadow 机制后,应用程序会有两个 CR3,一个为内核CR3,能够访问内核物理页,而三环的 CR3只映射了内核的.KVASCODE 区段的物理页(少数r3进入r0的入口),而没有映射其他区段的,因此通过 3 环的 Cr3 寻找内核 TEXT 段的物理页,最多只能找到 PPE,而从 PDE 开始就没有映射了。
如上图,当 CPL = 3 时,用户 CR3 可访问的地址空间及访问权限只是整个线性地址空间的一部分。两个 CR3 的位置如下:
- User CR3:
KPROCESS.UserDirectoryTableBase。 - Kernel CR3:
KTHREAD.SavedApcState.Process.DirectoryTableBase、KPRCR.KernelDirectoryTableBase。
KVA Shadow 起作用的地方主要在:
- 系统调用、用户空间触发的中断处理入口:用于将用户
UserDirectoryTableBase切换到内核KernelDirectoryTableBase。 - 从内核空间返回至用户空间出口:用于将内核
KernelDirectoryTableBase切换至用户UserDirectoryTableBase。
下面以 ntoskrnl.exe 中 .KVASCODE 和 .text 两个区段中的地址来解释两个 CR3:
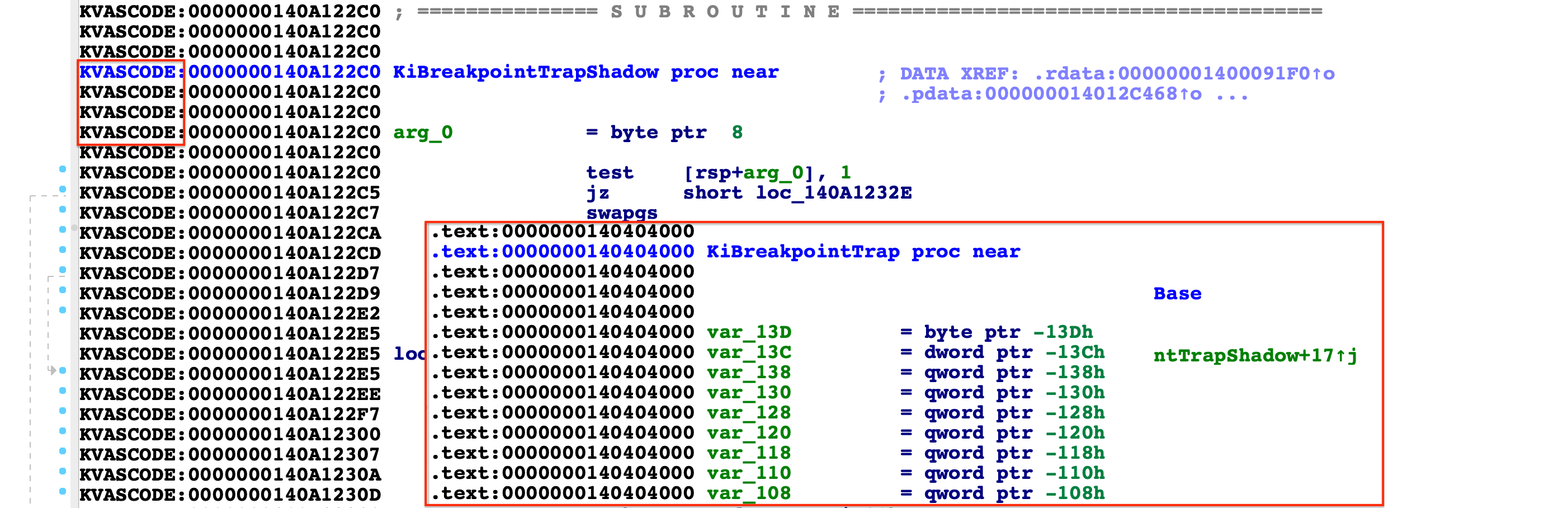
获取 CR3。
1
2
3
4
5
6
7
8
9
10
11kd> !process 0 0 notepad.exe
PROCESS ffffdb04799bd080
SessionId: 1 Cid: 0f94 Peb: ac473ef000 ParentCid: 0d28
DirBase: 2e269002 ObjectTable: ffffa88876245140 HandleCount: 238.
Image: notepad.exe
kd> dt nt!_EPROCESS ffffdb04799bd080 ImageFileName Pcb.DirectoryTableBase Pcb.UserDirectoryTableBase
+0x000 Pcb :
+0x028 DirectoryTableBase : 0x2e269002
+0x388 UserDirectoryTableBase : 0x66468001
+0x5a8 ImageFileName : [15] "notepad.exe"可以看到,这两个 CR3 下 PCID 值不一样,后面会讲到,这将用于性能优化。
- DirectoryTableBase:
PCID = 2。 - UserDirectoryTableBase:
PCID = 1。
- DirectoryTableBase:
获取
ntoskrnl.exe中.KVASCODE和.text两个区段不同函数的地址。1
2
3
4kd> ? nt!KiBreakpointTrapShadow
Evaluate expression: -8794360622400 = fffff800`674252c0
kd> ? nt!KiBreakpointTrap
Evaluate expression: -8794366969856 = fffff800`66e17800用
UserDirectoryTableBase解析这两个地址(注意:!vtop指令不识别十六进制地址的'符号)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// KiBreakpointTrapShadow
kd> !vtop 0x66468000 0xfffff800674252c0
Amd64VtoP: Virt fffff800674252c0, pagedir 0000000066468000
Amd64VtoP: PML4E 0000000066468f80
Amd64VtoP: PDPE 0000000079768008
Amd64VtoP: PDE 00000000797679d0
Amd64VtoP: PTE 000000007976e128
Amd64VtoP: Mapped phys 00000000036122c0
Virtual address fffff800674252c0 translates to physical address 36122c0.
// KiBreakpointTrap
kd> !vtop 0x66468000 0xfffff80066e17800
Amd64VtoP: Virt fffff80066e17800, pagedir 0000000066468000
Amd64VtoP: PML4E 0000000066468f80
Amd64VtoP: PDPE 0000000079768008
Amd64VtoP: PDE 00000000797679b8
Amd64VtoP: zero PDE
Virtual address fffff80066e17800 translation fails, error 0xD0000147.可以看到使用
UserDirectoryTableBase时,位于.text区段的函数KiBreakpointTrap地址没有对应的 PTE,没有进行映射。用
DirectoryTableBase解析这两个地址。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// KiBreakpointTrapShadow
kd> !vtop 0x2e269000 0xfffff800674252c0
Amd64VtoP: Virt fffff800674252c0, pagedir 000000002e269000
Amd64VtoP: PML4E 000000002e269f80
Amd64VtoP: PDPE 0000000000c89008
Amd64VtoP: PDE 0000000000c8a9d0
Amd64VtoP: PTE 0000000000c1c128
Amd64VtoP: Mapped phys 00000000036122c0
Virtual address fffff800674252c0 translates to physical address 36122c0.
// KiBreakpointTrap
kd> !vtop 0x2e269000 0xfffff80066e17800
Amd64VtoP: Virt fffff80066e17800, pagedir 000000002e269000
Amd64VtoP: PML4E 000000002e269f80
Amd64VtoP: PDPE 0000000000c89008
Amd64VtoP: PDE 0000000000c8a9b8
Amd64VtoP: PTE 0000000000c190b8
Amd64VtoP: Mapped phys 0000000003004800
Virtual address fffff80066e17800 translates to physical address 3004800.可以看到,使用
DirectoryTableBase时,两个不同区段的函数都进行了映射。
注意一个细节:.KVASCODE 区段中的虚拟地址、物理地址在两个 CR3 下面都是相同的,但是 PLM4E、PDPTE、PDE、PTE 不相同。
3.2 初始化KVA Shadow
KVAS 在启动(Boot)过程中就被初始化,会在操作系统初始化过程中被启用。NT 内核的入口点称为 KiSystemStartup,由操作系统加载器(OS Loader)调用。KiSystemStartup 依次执行一些基础的初始化步骤,其中的一个步骤就是调用 KilnitializeBootStructures。
在 KiInitializeBootStructures 将会调用 KiEnableKvaShadowing。KiEnableKvaShadowing 的功能是负责启用 KVAS,并设置 KiKvaShadow = 1。
在 KiEnableKvaShadowing 函数中(处理成功则返回 TRUE):
如果
KiIsKvaShadowDisabled = 1,表示禁用 KVA Shadow,则不会将KiKvaShadow = 1,直接返回1。如果KiIsKvaShadowDisabled = 0,则会将KiKvaShadow = 1。如果
KPRCB.Number = 0,即当前 CPU 编号为 0 时进行下面的步骤 3。否则会调用KiShadowProcessorAllocation映射 IDT.base、KernelDirectoryTableBase 的共享内存区对象,并设置KPRCB.ShadowFlags = 2,然后跳到步骤 6。调用
KiInitializeIdt函数,使用KiInterruptInitTable中的函数填充KiDebugTraps[KiDebugTrapIndex++] = v11,然后将中断处理例程(ISR)全部替换成 Shadow 版本。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37kd> !idt
Dumping IDT: fffff80069877000
00: fffff80067425100 nt!KiDivideErrorFaultShadow
01: fffff80067425180 nt!KiDebugTrapOrFaultShadow Stack = 0xFFFFF8006987B9D0
02: fffff80067425240 nt!KiNmiInterruptShadow Stack = 0xFFFFF8006987B7D0
03: fffff800674252c0 nt!KiBreakpointTrapShadow
04: fffff80067425340 nt!KiOverflowTrapShadow
05: fffff800674253c0 nt!KiBoundFaultShadow
06: fffff80067425440 nt!KiInvalidOpcodeFaultShadow
07: fffff800674254c0 nt!KiNpxNotAvailableFaultShadow
08: fffff80067425540 nt!KiDoubleFaultAbortShadow Stack = 0xFFFFF8006987B3D0
09: fffff800674255c0 nt!KiNpxSegmentOverrunAbortShadow
0a: fffff80067425640 nt!KiInvalidTssFaultShadow
0b: fffff800674256c0 nt!KiSegmentNotPresentFaultShadow
0c: fffff80067425740 nt!KiStackFaultShadow
0d: fffff800674257c0 nt!KiGeneralProtectionFaultShadow
0e: fffff80067425840 nt!KiPageFaultShadow
10: fffff800674258c0 nt!KiFloatingErrorFaultShadow
11: fffff80067425940 nt!KiAlignmentFaultShadow
12: fffff800674259c0 nt!KiMcheckAbortShadow Stack = 0xFFFFF8006987B5D0
13: fffff80067425ac0 nt!KiXmmExceptionShadow
14: fffff80067425b40 nt!KiVirtualizationExceptionShadow
15: fffff80067425bc0 nt!KiControlProtectionFaultShadow
1f: fffff80067425c40 nt!KiApcInterruptShadow
20: fffff80067425cc0 nt!KiSwInterruptShadow
29: fffff80067425d40 nt!KiRaiseSecurityCheckFailureShadow
2c: fffff80067425dc0 nt!KiRaiseAssertionShadow
2d: fffff80067425e40 nt!KiDebugServiceTrapShadow
2f: fffff80067425f40 nt!KiDpcInterruptShadow
30: fffff80067425fc0 nt!KiHvInterruptShadow
31: fffff80067426040 nt!KiVmbusInterrupt0Shadow
32: fffff800674260c0 nt!KiVmbusInterrupt1Shadow
33: fffff80067426140 nt!KiVmbusInterrupt2Shadow
34: fffff800674261c0 nt!KiVmbusInterrupt3Shadow
35: fffff80067426468 nt!HalpInterruptCmciService (KINTERRUPT fffff80067705fc0)先将
KiFlushPcid = 1。如果KPRCB.FeatureBits & 240000000000h = 240000000000h则将KiFlushPcid = 2。设置
KiKvaShadowMode的值。1
2
3
4
5
6
7if(KiFlushPcid != 0)
{
KiKvaShadowMode = 1;
}else
{
KiKvaShadowMode = 2;
}设置
KPRCB.KernelDirectoryTableBase的 Bit63。1
2
3
4
5// 则将 bit63 = 1,不刷新 TLB 和分页结构缓存
if(KiFlushPcid != 0)
{
KPRCB.KernelDirectoryTableBase &= 63;
}
上述初始化好后,返回到函数 KiInitializeBootStructures 继续进行初始化系统调用的入口函数。
在已经开启 KVA Shadow 的情况下:
- 先将
KiSystemCall32Shadow/KiSystemCall64Shadow保存到全局指针KiDebugTraps指向索引为6/5的位置。 - 然后修改 MSR 的
IA32_STAR/IA32_LSTAR/IA32_FMASK寄存器,将系统调用入口全部替换为Shadow版本(如果不开启KVAS则不替换为Shadow版本)。
1 | rbx = &KiSystemCall32; |
3.3 CR3 切换分析
KVA Shadow: Mitigating Meltdown on Windows建议了解 KVAS最好是从中断处理、系统调用开始。与 KVA Shadow 最相关的事件是那些称为“内核进入”和“内核退出”事件的事件。这些事件分别涉及从用户模式过渡到内核模式,以及从内核模式过渡到用户模式。
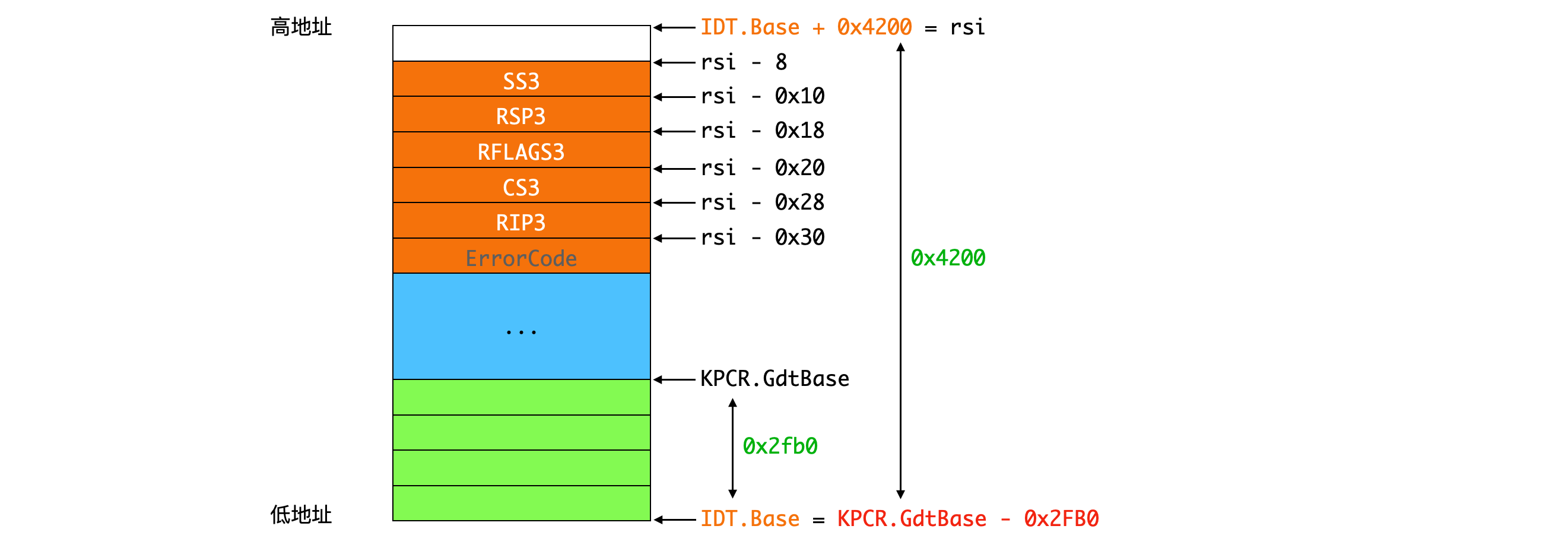
如下图,系统调用、中断处理从用户模式刚进入内核模式阶段的状态。需要在关中断的状态下立即从 UserDirectoryTableBase 切换到内核 KernelDirectoryTableBase。
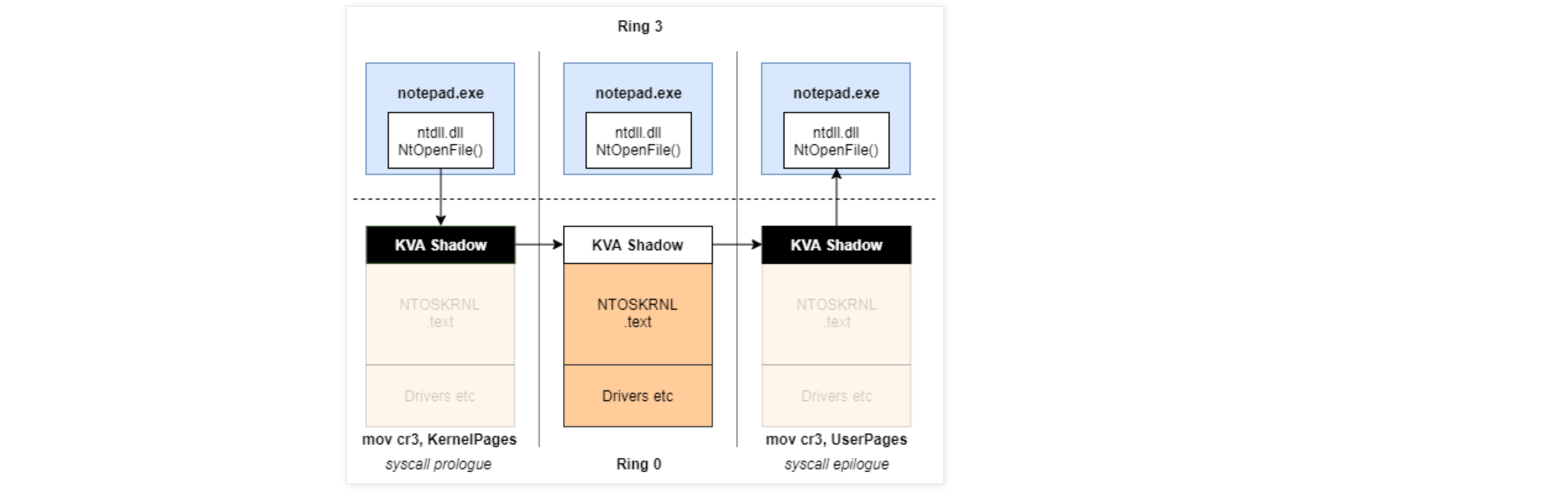
下面就以 3 号中断 KiBreakpointTrapShadow 处理函数为例进行分析:
1 | kd> dqs KiDebugTraps |
KiBreakpointTrapShadow 函数:
1 | KVASCODE:0000000140A122C0 // =============== S U B R O U T I N E ======================================= |
KiEnableKvaShadowing 函数:
1 | PAGELK:000000014099CFDC // =============== S U B R O U T I N E ======================================= |
通过以上两个函数的分析,GDT、IDT 表在内存中的起始地址有如下关系,在中断处理中硬件压栈的 5 个参数(ErrorCode仅对8,17号中断压栈,但是在堆栈上空间预留)会保存在如下 IDT.base + 0x4200 - 8 开始的位置。
在中断处理函数,如函数 KiBreakpointTrapShadow 中会将中断时硬件压栈的这 5 个参数拷贝至新的堆栈中。
1 | // 先进行堆栈切换 |
3.4 性能加速
一、支持 PCID 机制的 CPU(CR4.PCIDE = 1)
由于系统调用频繁地发生,UserDirectoryTableBase 与 KernelDirectoryTableBase 的切换会在一定程度上损耗性能。所以在支持PCID 并需要 KVA Shadow 的硬件上,Windows 内核使用两个不同的 PCID 值,内部称为 PCID_KERNEL 和 PCID_USER,从上面的分析可以看到:
- PCID_KERNEL = 2,即 KiFlushPcid = 2,CR3[bit 63] = 1。
- PCID_USER = 1,即 KiFlushPcid = 1,CR3[bit 63] = 1。
这样在模式切换后,先前模式下的 TLB、Page struct-cache、全局页面不用刷新。但是注意:不同进程的线程切换时,CPU 上的 TLB 必须刷新。
二、不支持 PCID 机制的 CPU(CR4.PCIDE = 0)
不支持 PCID 机制的 CPU 上,也就没有 Page struct-cache。只能依靠 TLB 上的全局页面来进行性能加速。传统方式下,一般是共享的内核页面才更有可能作为全局页面地址转换信息缓存在 TLB 中,但是在支持 KVA Shadow 的系统中,而是将用户页面标记为全局页面。
三、特权应用程序加速
当程序以管理员身份(特权级)运行时,只有一个 KernelDirectoryTableBase,不会使用到 UserDirectoryTableBase。
ntoskrnl 中,切换上下文的函数 KiSwapContext 调用 SwapContext:
KiKvaShadow = 1 下:
AddressPolicy > 0,特权权限程序 —> ShadowFlags = 1。
AddressPolicy = 0,一般权限程序 —> ShadowFlags = 3。
1 | // SwapContext |
参考:
4 CPU 推测执行漏洞
虽然 Meltdown(熔毁,CVE-2017-5754)、Spectre(幽灵,CVE-2017-5753&CVE-2017-5715)漏洞在发现时间上存在前后关系,但是在后来的研究以及漏洞缓解实施过程中,都将这些漏洞统称为 CPU 推测执行的变体(CPU Speculative execution Variant)。
参考:
- 《Mitigating Risk of Spectre and Meltdown Vulnerabilities》
- 《007: Low-overhead Defense against Spectre Attacks via Program Analysis》
| 变体(Variant) | CVE | 原理 | 缓解措施 |
|---|---|---|---|
| 1 | CVE-2017-5753(Spectre) | 在有分支判断的地方,代码编译为 JCC 条件跳转指令。攻击者可以通过循环训练 CPU 对跳转的训练,最后利用 CPU 来推测执行 JCC 的目的地。 |
软件缓解:Microsoft Visual C/C++ 编译器提供了一个编译选项 Qspectre,通过在潜在易受攻击的代码位置插入 lfence 序列化指令来启用缓解。 |
| 2 | CVE-2017-5715(Spectre) | 在有间接跳转或调用,如 jmp rax/jmp [rax]/call rax/call [rax]/ret 等间接分支时,CPU 利用 BTB、RSB 中的信息进行预测并跳转。攻击者可以污染 BTB、RSB 来修改跳转目的地,从而实施攻击。 |
软件缓解: 1、使用 Retpoline 将易受攻击的间接分支替换为非易受攻击的指令序列,强制 CPU 跳转到真实目的地而不是 BTB/RSB 建议的预测目标。 2、使用 lfence 指令(可选择)。3、RSB 填充 + BTB 刷新。 硬件缓解: 1、IBPB:同一权限级别下,之前的跳转地址不会影响之后的跳转预测。 2、IBRS:内核权限代码不得使用分支预测器中的用户代码,用户权限代码也不得使用分支预测器中的内核代码。 |
| 3 | CVE-2017-5754(Meltdown) | 在指令中,如果前后指令不存在依赖关系,如果前面一条指令需要访问内存或导致异常时,CPU 有可能已经执行了乱序执行了后面的指令。攻击者可以利用瞬态指令来泄露内核数据。 | 软件缓解:KVA Shadow、lfence 指令(乱序之行)。 |
5 Spectre 缓解措施
5.1 lfence 指令
lfence :lfence 前的指令必须在它之后指令前执行。
该指令常用在分支预测 JCC 之后防止推测执行,在文《Bypassing KPTI Using the Speculative Behavior of the SWAPGS Instruction》中报告了集中利用 CPU 在 swapgs 指令执行时推测执行后面代码的漏洞,所以一般在 swapgs 指令前后都会有 lfence 指令。
如下代码,swapgs 必须在 bt 指令前执行。
1 | KVASCODE:0000000140A122C7 swapgs |

可以用来缓解 CPU 的推测执行,包括缓解熔断和幽灵漏洞,但是会有稍稍的性能影响。
5.2 RSB 刷新 + BTB 刷新(v2)
在有如 jmp rax/jmp [rax]/call rax/call [rax]/ret 等间接分支时,跳转地址在运行时才能确定。但是 CPU 中使用 BTB、RSB 两个结构来进行预测跳转。
- 分支目标缓冲区(Branch Target Buffer,BTB):保存预测指令预测的跳转地址。处理器甚至可以在解码分支指令之前使用 BTB 来预测未来的代码地址。
- 返回堆栈缓冲区(Return Stack Buffer,RSB):维护最近使用的调用堆栈返回地址的副本,专门用于
call/ret指令。如果 RSB 中没有可用数据,不同的处理器将停止执行或使用 BTB 作为后备。
一、RSB 刷新:
因为 RSB 是一个 32 个槽的循环 buffer,因此只需要 32 个虚假的 call 指令就可以把整个 RSB 清理一遍。
在函数 KiSystemCall64Shadow 中就有使用(其中 add rsp, 8 用来模拟 ret):
1 | KVASCODE:0000000140A14291 loc_140A14291: // CODE XREF: KiSystemCall64Shadow+FC↑j |
二、BTB 刷新
BTB 的槽从 1K 到 16K 不等,而且从虚拟地址到 BTB 索引的映射函数f(x)还不公开,因此要清除 BTB,需要首先使用逆向工程方法找到 f(x),然后根据 f(x) 找到 1k 到 16K 的虚拟地址来对应每个 BTB 的槽。最后发起 1K 到 16K 个虚假的 call/jmp 把所有 BTB 的槽清空(如下图)。需要指出,该方案的性能 overhead 很大。在内核代码中也没有看到这种大消耗的代码片段,所以只有在代码中尽量少使用间接跳转/调用(可以使用 Retpoline 技术缓解)。

参考:
5.3 Retpoline 技术(v2)
该技术是 Google 提出的,以毒攻毒的解法。
两个示例,对于间接跳转 jmp r11/call r11。
jmp r11。使用 Retpoline 技术可以修改为:
1
2
3
4
5
6
7call set_up_target; (1)
capture_spec: (4)
pause;
jmp capture_spec;
set_up_target:
mov qword ptr [rsp], r11; (2)
ret; (3)由于(3)处的
ret也是潜在的被攻击目标(基于RSB预测目标的注入),因此 indirect branch thunk 需要将解决方案闭环。- (1):是一个近跳转(near jmp),跳转目标在代码编译时硬编码写好的,不会使用到 BTB。然后将
capture_spec压栈,同时(4)的地址也会压入 RSB 中。 - (2):该指令访问内存不存在分支,也就不会进行预测执行。此时会将栈顶的返回地址修改为真正的跳转目标 r11,但这个操作不会改变 RSB 中的值。
- (3):此时存在推测执行,推测执行的目的地是
capture_spec,推测执行的瞬态指令是一个死循环。当ret真正执行时,会跳转至 r11,然后丢弃推测执行的结果。(4)中没有访问内存(fetch指令不是read Memory),也就没有存高速缓存的过程。
- (1):是一个近跳转(near jmp),跳转目标在代码编译时硬编码写好的,不会使用到 BTB。然后将
call r11。使用 Retpoline 技术可以修改为:
1
2
3
4
5
6
7
8
9
10
11
12
13jmp set_up_return; (1)
inner_indirect_branch:(3)
call set_up_target; }
capture_spec: }
pause; }
jmp capture_spec; } Indirect branch
set_up_target: } sequence.
mov qword ptr [rsp], r11; }
ret; }
set_up_return:
call inner_indirect_branch (2)本质上,indirect call thunk 的内部实现还是 indirect branch thunk,只不过为了维持 call 指令的语义,必须增加(1)这样的跳转指令调到(2)处,将 call 指令真正的返回地址,即利用(2)将原先返回地址压入栈顶(原先call r11的返回地址),同时跳转到(3)处开始执行 indirect branch thunk。
将上面的解决方案进行封装:
先将 indirect thunk 封装:
1 | retpoline_r11_trampoline: |
然后将 jmp r11/call r11 分别替换成 jmp/call retpoline_r11_trampoline 即可。
在函数 _guard_icall_handler、__guard_retpoline_indirect_cfg_rax 中有使用到:
1 | RETPOL:0000000140A152A0 __guard_retpoline_indirect_cfg_rax proc near |
参考:
深入分析Spectre变体2漏洞缓解方案:Google Retpoline构造技术。
Retpoline: a software construct for preventing branch-target-injection。
5.4 IBRS、IBPB
硬件缓解:
1、IBPB:同一权限级别下,之前的跳转地址不会影响之后的跳转预测。
2、IBRS:内核权限代码不得使用分支预测器中的用户代码,用户权限代码也不得使用分支预测器中的内核代码。
CPUID.(EAX=7H,ECX=0):EDX[26] = 1 则表示支持 IBRS 和 IBPB(需要在较新的 CPU 上)。其中 IBRS 位于 IA32_SPEC_CTRL[0](48H) MSR ,IBPB 位于 IA32_SPEC_CTRL[0](49H) MSR。
参考:
幽灵漏洞(二) 。
Speculative Execution Side Channel Mitigations—Revision 2.0。
Speculative Execution Side Channel Mitigations—Revision 3.0。
6 SMEP、SMAP、NX
CR4.SMEP(Supervisor Mode Executions Protection Enable)
- SMEP = 1,在 R0 权限的程序不可以执行 R3 中 PTE.XD = 0 的页面上的代码。
- SMEP = 0,在 R0 权限的程序可以执行 R3 中 PTE.XD = 0 的页面上的代码。
CR4.SMAP(Supervisor Mode Access Protection Enable)
- SMEP = 1,在 R0 权限的程序不可以访问 R3 中 PTE.XD = 0 的页面上的代码。
- SMEP = 0,在 R0 权限的程序可以访问 R3 中 PTE.XD = 0 的页面上的代码。
- 从用户模式构造中断门进入内核后,由于当前的
CR3 = UserDirectoryTableBase,但是CPL = 0,默认情况下CR4.SMEP = 1, CR4.SMAP = 1。提前在 3 环构造的函数在UserDirectoryTableBase下具有执行权限,也就是PLM4E.NX | PDPTE.NX | PDE.NX | PTE.NX = 0。 - 但是如果从
UserDirectoryTableBase切换到KernelDirectoryTableBase后,该 CR3 下对用户空间的所有地址都是没有执行权限的。如下图。