数据库编译原理和注入
ʕ •ᴥ•ʔ (๑˃̵ᴗ˂̵) ପ( ˘ᵕ˘ ) ੭
1 数据库预编译
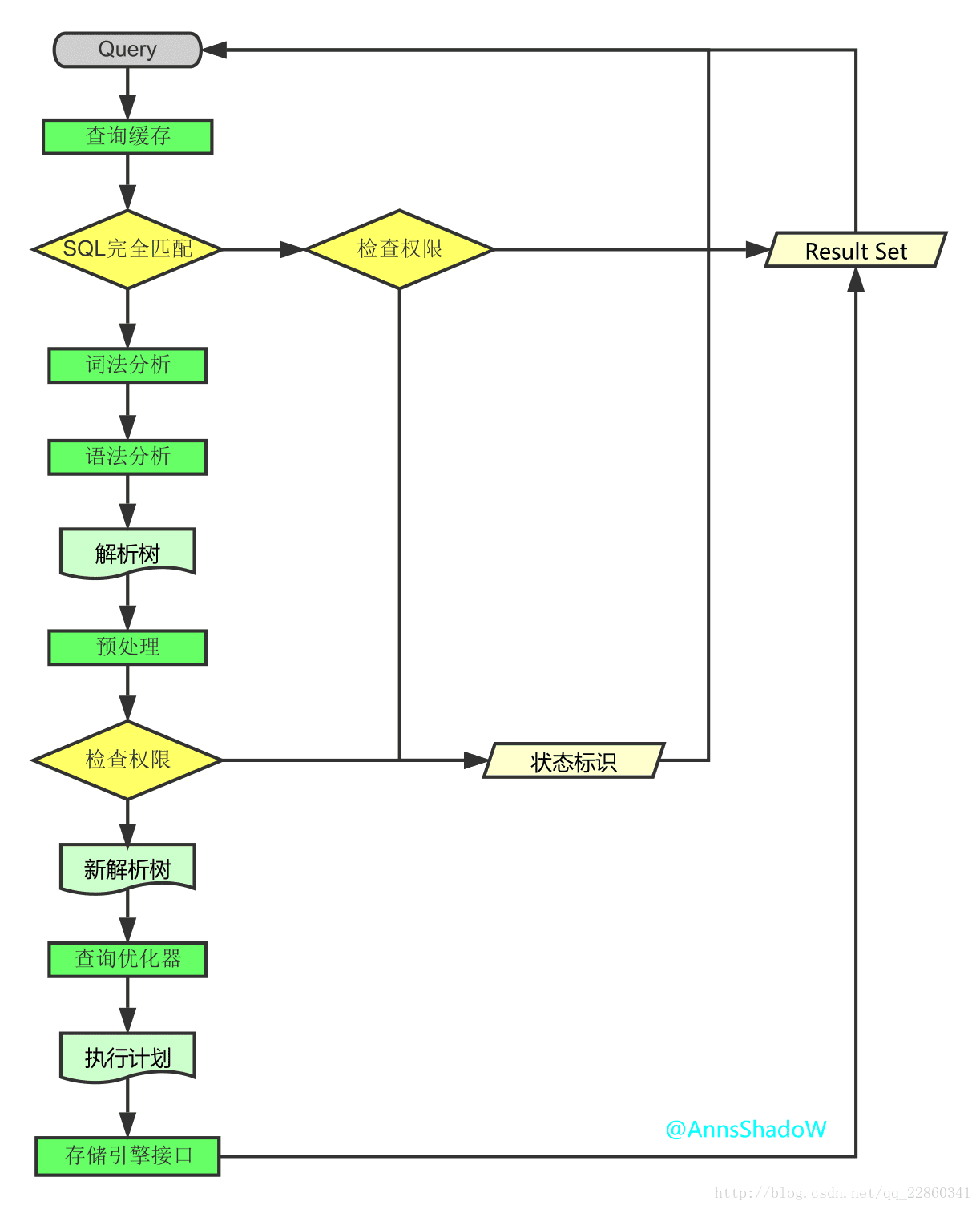
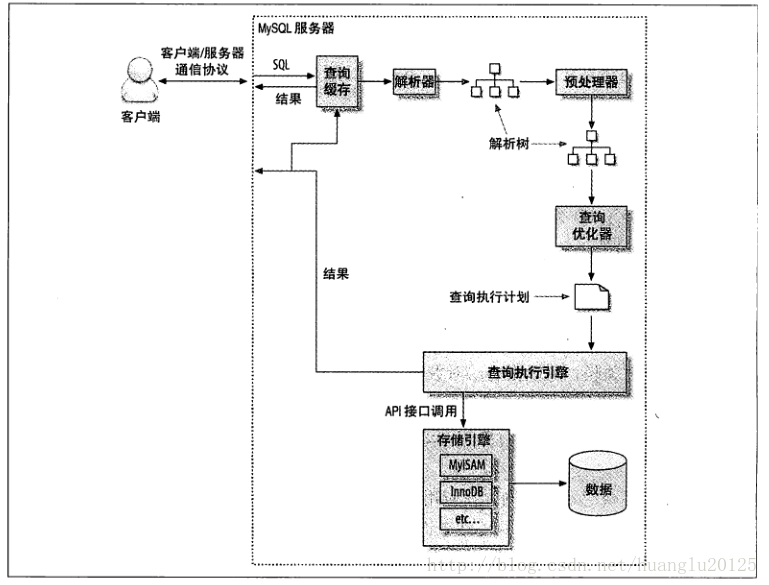
MySQL查询执行路径
- 客户端发送一条查询给服务器;
- 服务器先会检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果。否则进入下一阶段;
- 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划;
- MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询;
- 将结果返回给客户端。
1.1 查询高速缓存(library cache)
服务器进程在接到客户端传送过来的 SQL 语句时,不会直接去数据库查询。而是会先在数据库的高速缓存中去查找,是否存在相同语句的执行计划。如果在数据高速缓存中,则服务器进程就会直接执行这个 SQL 语句,省去后续的工作。所以,采用高速数据缓存的话,可以提高 SQL 语句的查询效率。一方面是从内存中读取数据要比从硬盘中的数据文件中读取数据效率要高,另一方面,也是因为这个语句解析的原因。
如果当前的查询恰好命中了查询缓存,那么在返回查询结果之前 MySQL 会检查一次用户权限。这仍然是无须解析查询 SQL 语句的,因为在查询缓存中已经存放了当前查询需要访问的表信息。如果权限没有问题,MySQL 会跳过所有其他阶段,直接从缓存中拿到结果并返回给客户端。这种情况下,查询不会被解析,不用生成执行计划,不会被执行。
不过这里要注意一点,这个数据缓存跟有些客户端软件的数据缓存是两码事。有些客户端软件为了提高查询效率,会在应用软件的客户端设置数据缓存。由于这些数据缓存的存在,可以提高客户端应用软件的查询效率。但是,若其他人在服务器进行了相关的修改,由于应用软件数据缓存的存在,导致修改的数据不能及时反映到客户端上。从这也可以看出,应用软件的数据缓存跟数据库服务器的高速数据缓存不是一码事。
1.2 语法解析器
ANTLR—Another Tool for Language Recognition,其前身是PCCTS,它为包括Java,C++,C#在内的语言提供了一个通过语法描述来自动构造自定义语言的识别器(recognizer),编译器(parser)和解释器(translator)的框架。
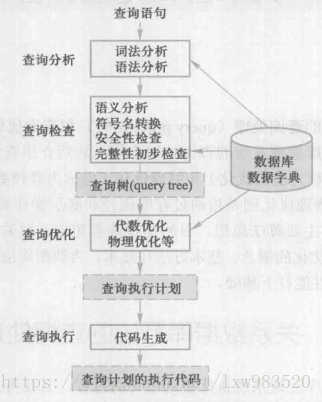
词法分析器(Parser): 词法分析器又称为 Scanner,Lexical analyser 和 Tokenizer。程序设计语言通常由关键字和严格定义的语法结构组成。编译的最终目的是将程序设计语言的高层指令翻译成物理机器或虚拟机可以执行的指令。词法分析器的工作是分析量化那些本来毫无意义的字符流,将他们翻译成离散的字符组(也就是一个一个的Token),包括关键字,标识符,符号(symbols)和操作符供语法分析器使用。词法分析阶段是编译过程的第一个阶段。这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。
语法分析器(Parser): 编译器又称为 Syntactical analyser。在分析字符流的时候,Lexer 不关心所生成的单个 Token 的语法意义及其与上下文之间的关系,而这就是 Parser 的工作。语法分析器将收到的 Tokens 组织起来,并转换成为目标语言语法定义所允许的序列。语法分析是编译过程的一个逻辑阶段。语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如程序,语句,表达式等等。语法分析程序判断源程序在结构上是否正确。源程序的结构由上下文无关文法描述。
无论是 Lexer 还是 Parser 都是一种识别器,Lexer 是字符序列识别器而 Parser 是 Token 序列识别器。他们在本质上是类似的东西,而只是在分工上有所不同而已。
1.3 预处理
预处理:也叫做语义分析,预处理由预处理器来完成,预处理器则根据一些 MySQL 规则进一步检查解析树是否合法,例如,这里讲检查数据表和数据列是否存在,还会解析名字和别名,看看它们是否有歧义。语言含义检查(Data Dict Cache)。若 SQL 语句符合语法上的定义的话,则服务器进程接下去会对语句中的字段、表等内容进行检查,看看这些字段、表是否在数据库中。如果表名与列名不准确的话,则数据库会就会反馈错误信息给客户端。所以,有时候我们写 select 语句的时候,若语法与表名或者列名同时写错的话,则系统是先提示说语法错误,等到语法完全正确后,再提示说列名或表名错误。
对合法的查询语句进行语义查询,即根据数据字典中有关的模式定义检查语句中的数据库对象(关系名、属性名)是否存在和有效。如果是对视图的操作,要用视图消解方法把对视图的操作转换成对基本表的操作。还要根据数据字典中的用户权限和完整性约束定义对用户的存取权限进行检查。如果对该用户没有相应的防伪权限或违反了完整性约束,就拒绝执行该查询。当然,这时的完整性检查是初步、静态的检查。检查通过后便把 SQL 查询语句转换成内部表示,即等价的关系代数表达式。这个过程中要把数据库对象的外部名称转换为内部表示。关系数据库管理系统一般都用查询树,也称为语法分析树来表示扩展的关系代数表达式。
关键点:
- SQL解析包括语法分析器和词法分析器。
简便的做法是用 bison/flex 组合。不过MySQL的词法分析器是手工打造的。
语法分析器的入口函数是 MYSQLparse,词法分析器的入口函数是 MYSQLlex。 - 词法分析中会检查 token 是否为关键字。
最直接的做法是弄个大的关键字数组,进行折半查找。MySQL 在此做了些优化。
本文主要介绍的是这一部分。
- 【MySQL: Query Parsing】
- 【揭秘:一条SQL语句的执行过程是怎么样的?】
- 【SQL查询执行流程】
- 【MySQL-词法分析】
- 【词法分析、语法分析、语义分析】
- 【SQL - 词法/语法分析各种方案总结】
- 【数据库查询语言SQL的语法分析及实现】
- 【MySQL查询执行过程】
- 【MySQL 查询执行的流程】
- 【关系数据库的查询处理】
- 【数据库—关系查询处理和查询优化】
- 【查询执行流程->SQL解析顺序】
1.4 权限检查
数据访问权限的核对。当语法、语义通过检查之后,客户端还不一定 能够取得数据。服务器进程还会检查,你所连接的用户是否有这个数据访问的权限。若你连接上服务器的用户不具有数据访问权限的话,则客户端就不能够取得这些数据。有时候我们查询数据的时候,辛辛苦苦地把 SQL 语句写好、编译通过,但是最后系统返回 “没有权限访问数据”的错误信息,则半途而废。
1.5 查询优化和执行计划生成
查询优化器现在语法树被认为合法的了,并且由优化器将其转化为执行计划。一条查询可以由很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
在查询优化阶段,MySQL 将生成查询对应的执行计划。
MySQL 使用基于成本的优化器,它将尝试预测一个查询使用某种执行计划的成本,并选择其中成本最小的一个。最初,成本的最小单位是随机读取一个4K数据页的成本,后来成本计算公式变得更加复杂,并且引入了一些“因子”来估算某些操作的代价,如当执行一次where条件比较的成本。可以通过查询当前会话的last_query_cost的值来得知 MySQL 计算的当前查询的成本。 有很多种原因会导致 MySQL 优化器选择错误的执行计划,比如:
- 统计信息不准确。
- 执行计划中的成本估算不等同于实际的执行计划的成本。
- MySQL 的最优可能与你想的最优不一样。
- MySQL 从不考虑其他并发的查询,这可能会影响当前查询的速度。
- MySQL 也不是任何时候都是基于成本的优化,有时候也会基于一些固定的规则。
- MySQL 不会考虑不受其控制的成本,例如执行存储过程或者用户自定义的函数的成本。
MySQL 的查询优化使用了很多优化策略来生成一个最优的执行的计划。优化策略可以分为两种,静态优化和动态优化。静态优化可以直接对解析树进行分析,并完成优化。例如优化器可以通过一些简单的代数变换将where条件转换成另一种等价形式。静态优化不依赖于特别的数值,如where条件中带入的一些常数等。静态优化在第一次完成后就一直有效,即使使用不同的参数重复查询也不会变化,可以认为是一种“编译时优化”。 相反,动态优化则和查询的上下文有关。也可能和很多其他因素有关,例如where条件中的取值、索引中条目对应的数据行数等,这些需要每次查询的时候重新评估,可以认为是“运行时优化”。
- 静态优化
直接对解析树进行分析,并完成优化。例如优化器可以通过一些简单的代数变换将 where 条件转换成另一种等价形式。静态优化不依赖于特别的数值,如 where 条件中带入的一些常数等。静态优化在第一次完成后就一直有效,即使使用不同的参数重复查询也不会变化,可以认为是一种编译时优化 - 动态优化
动态优化与查询的上下文有关,也可能和很多其他因素有关,例如 where 条件中的取值、索引中条目对应的数据行数等,这些每次查询的时候都需要重新评估,可以认为是运行时优化
1.6 查询执行引擎
在解析和优化阶段,MySQL将生成查询对应的执行计划,MySQL的查询执行引擎则根据这个执行计划来完成整个查询。这里执行计划是一个数据结构,而不是和很多其他的关系型数据库那样会生成对应的字节码。
相对于查询优化阶段,查询执行阶段不是那么复杂:MySQL只是简单的根据执行计划给出的指令逐步执行。在根据执行计划逐步执行的过程中,有大量的操作需要通过调用存储引擎实现的接口来完成,这些接口就是我们称为handler API的接口。实际上,MySQL在优化阶段就为每个表创建了一个handler实例,优化器根据这些实例的接口可以获取表的相关信息,包括表的所有列名、索引统计信息等。
1.7 返回结果给客户端
查询执行的最后一个阶段是将结果返回给客户端。即使查询不需要返回结果给客户端,MySQL 仍然会返回这个查询的一些信息,如查询影响到的行数。如果查询可以被缓存,那么 MySQL 在这个阶段,会将结果存放到查询缓存中。MySQL 将结果返回客户端是一个增量、逐步返回的过程。例如,在关联表操作时,一旦服务器处理完最后一个关联表,开始生成第一条结果时,MySQL就可以开始向客户端逐步返回结果集了。这样处理有两个好处:服务器无需存储太多的结果,也就不会因为要返回太多的结果而消耗太多的内存。另外,这样的处理也让 MySQL 客户端第一时间获得返回的结果。结果集中的每一行都会以一个满足 MySQL 客户端/服务器通信协议的封包发送,再通过 TCP 协议进行传输,在 TCP 传输过程中,可能对 MySQL 的封包进行缓存然后批量传输。
2 预编译防御SQL注入

学习总结SQL注入的防范原理
一般的注入分类:数字型、字符型、GET注入、POST注入、Cookie注入、HTTP头部注入、基于布尔的注入、基于时间的注入、基于报错的注入、联合查询注入、堆查询注入、宽字节注入。
我总结将其分类两个大类:回显注入(注入过程中前端能看到回显内容)、盲注(注入过程中前端不能看到回显内容),而把其他分类归结为使用的注入方法。
典型的攻击流程如下:
- 判断 Web 系统使用的脚本语言,发现注人点,并确定是否存在 SQL 注人漏洞。
- 判断 Web 系统的数据库类型。
- 判断数据库中表及相应字段的结构。
- 构造注入语句,得到表及相应字段的结构表中数据内容。
- 查找网站后台管理员,用得到的管理员账号和密码登录。
- 结合其他漏洞,上传Webshell并持续连接(留后门)。
- 进一步提权,得到服务器的系统权限。
防御方法:
- 早期的常规方法和现在一些中小型企业的网站使用的防范方式是在服务器做SQL代码过滤、安全编码、字符转义、字符替换、参数类型限制、参数长度限制、使用正则表达式等,往往达不到预期的防范效果。
- 目前相对成熟的防范方法是在代码层使用开发框架、数据库预编译之后参数化查询、使用存储过程、URL重写,在网络架构上使用WAF和防火墙等设备。还有一些目前研究先进的防御方法,如基于改进的模式匹配算法、污点分析算法、机器学习、抽象语法树的SQL防范技术等。